Binomial proportion confidence interval
In statistics, a binomial proportion confidence interval is a confidence interval for the probability of success calculated from the outcome of a series of success–failure experiments (Bernoulli trials). In other words, a binomial proportion confidence interval is an interval estimate of a success probability p when only the number of experiments n and the number of successes nS are known.
There are several formulas for a binomial confidence interval, but all of them rely on the assumption of a binomial distribution. In general, a binomial distribution applies when an experiment is repeated a fixed number of times, each trial of the experiment has two possible outcomes (success and failure), the probability of success is the same for each trial, and the trials are statistically independent. Because the binomial distribution is a discrete probability distribution (i.e., not continuous) and difficult to calculate for large numbers of trials, a variety of approximations are used to calculate this confidence interval, all with their own tradeoffs in accuracy and computational intensity.
A simple example of a binomial distribution is the set of various possible outcomes, and their probabilities, for the number of heads observed when a coin is flipped ten times. The observed binomial proportion is the fraction of the flips that turn out to be heads. Given this observed proportion, the confidence interval for the true probability of the coin landing on heads is a range of possible proportions, which may or may not contain the true proportion. A 95% confidence interval for the proportion, for instance, will contain the true proportion 95% of the times that the procedure for constructing the confidence interval is employed.[1]
Normal approximation interval
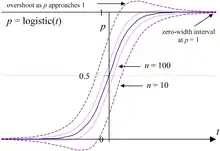
A commonly used formula for a binomial confidence interval relies on approximating the distribution of error about a binomially-distributed observation, , with a normal distribution.[3] This approximation is based on the central limit theorem and is unreliable when the sample size is small or the success probability is close to 0 or 1.[4]

Using the normal approximation, the success probability p is estimated as

or the equivalent

where is the proportion of successes in a Bernoulli trial process, measured with trials yielding successes and failures, and is the quantile of a standard normal distribution (i.e., the probit) corresponding to the target error rate . For a 95% confidence level, the error , so and .










An important theoretical derivation of this confidence interval involves the inversion of a hypothesis test. Under this formulation, the confidence interval represents those values of the population parameter that would have large p-values if they were tested as a hypothesized population proportion. The collection of values, , for which the normal approximation is valid can be represented as


where is the quantile of a standard normal distribution. Since the test in the middle of the inequality is a Wald test, the normal approximation interval is sometimes called the Wald interval, but it was first described by Pierre-Simon Laplace in 1812.[5]


Standard error of a proportion estimation when using weighted data
Let there be a simple random sample where each is i.i.d from a Bernoulli(p) distribution and weight is the weight for each observation. Standardize the (positive) weights so they sum to 1. The weighted sample proportion is: . Since the are independent and each one has variance , the sampling variance of the proportion therefore is:[6]





.

The standard error of is the square root of this quantity. Because we do not know , we have to estimate it. Although there are many possible estimators, a conventional one is to use , the sample mean, and plug this into the formula. That gives:


For unweighted data, , giving . The SE becomes , leading to the familiar formulas, showing that the calculation for weighted data is a direct generalization of them.



Wilson score interval

The Wilson score interval is an improvement over the normal approximation interval in multiple respects. It was developed by Edwin Bidwell Wilson (1927).[7] Unlike the symmetric normal approximation interval (above), the Wilson score interval is asymmetric. It does not suffer from problems of overshoot and zero-width intervals that afflict the normal interval, and it may be safely employed with small samples and skewed observations.[3] The observed coverage probability is consistently closer to the nominal value, .[2]

Like the normal interval, but unlike the Clopper-Pearson interval, the interval can be computed directly from a formula.
Wilson started with the normal approximation to the binomial:

with the analytic formula for the sample standard deviation given by
- .

Combining the two, and squaring out the radical, gives an equation that is quadratic in p:

Transforming the relation into a standard-form quadratic equation for p, treating and n as known values from the sample (see prior section), and using the value of z that corresponds to the desired confidence for the estimate of p gives this:
- ,

where all of the values in parentheses are known quantities. The solution for p estimates the upper and lower limits of the confidence interval for p. Hence the probability of success p is estimated by

or the equivalent

The practical observation from using this interval is that it has good properties even for a small number of trials and / or an extreme probability.
Intuitively, the center value of this interval is the weighted average of and , with receiving greater weight as the sample size increases. Formally, the center value corresponds to using a pseudocount of 1/2 z², the number of standard deviations of the confidence interval: add this number to both the count of successes and of failures to yield the estimate of the ratio. For the common two standard deviations in each direction interval (approximately 95% coverage, which itself is approximately 1.96 standard deviations), this yields the estimate , which is known as the "plus four rule".


Although the quadratic can be solved explicitly, in most cases Wilson's equations can also be solved numerically using the fixed-point iteration

with .

The Wilson interval can also be derived from the single sample z-test or Pearson's chi-squared test with two categories. The resulting interval,

can then be solved for to produce the Wilson score interval. The test in the middle of the inequality is a score test.
The interval equality principle

Since the interval is derived by solving from the normal approximation to the binomial, the Wilson score interval has the property of being guaranteed to obtain the same result as the equivalent z-test or chi-squared test.

This property can be visualised by plotting the probability density function for the Wilson score interval (see Wallis 2021: 297-313)[8] and then plotting a normal pdf at each bound. The tail areas of the resulting Wilson and normal distributions, representing the chance of a significant result in that direction, must be equal.
The continuity-corrected Wilson score interval and the Clopper-Pearson interval are also compliant with this property. The practical import is that these intervals may be employed as significance tests, with identical results to the source test, and new tests may be derived by geometry.[8]
Wilson score interval with continuity correction
The Wilson interval may be modified by employing a continuity correction, in order to align the minimum coverage probability, rather than the average coverage probability, with the nominal value, .
Just as the Wilson interval mirrors Pearson's chi-squared test, the Wilson interval with continuity correction mirrors the equivalent Yates' chi-squared test.
The following formulae for the lower and upper bounds of the Wilson score interval with continuity correction are derived from Newcombe (1998).[2]


However, if p = 0, must be taken as 0; if p = 1, is then 1.


Wallis (2021)[8] identifies a simpler method for computing continuity-corrected Wilson intervals that employs functions. For the lower bound, let , where is the selected error level for . Then . This method has the advantage of being further decomposable.


Jeffreys interval
The Jeffreys interval has a Bayesian derivation, but it has good frequentist properties. In particular, it has coverage properties that are similar to those of the Wilson interval, but it is one of the few intervals with the advantage of being equal-tailed (e.g., for a 95% confidence interval, the probabilities of the interval lying above or below the true value are both close to 2.5%). In contrast, the Wilson interval has a systematic bias such that it is centred too close to p = 0.5.[9]
The Jeffreys interval is the Bayesian credible interval obtained when using the non-informative Jeffreys prior for the binomial proportion p. The Jeffreys prior for this problem is a Beta distribution with parameters (1/2, 1/2), it is a conjugate prior. After observing x successes in n trials, the posterior distribution for p is a Beta distribution with parameters (x + 1/2, n – x + 1/2).
When x ≠0 and x ≠ n, the Jeffreys interval is taken to be the 100(1 – α)% equal-tailed posterior probability interval, i.e., the α / 2 and 1 – α / 2 quantiles of a Beta distribution with parameters (x + 1/2, n – x + 1/2). These quantiles need to be computed numerically, although this is reasonably simple with modern statistical software.
In order to avoid the coverage probability tending to zero when p → 0 or 1, when x = 0 the upper limit is calculated as before but the lower limit is set to 0, and when x = n the lower limit is calculated as before but the upper limit is set to 1.[4]
Clopper–Pearson interval
The Clopper–Pearson interval is an early and very common method for calculating binomial confidence intervals.[10] This is often called an 'exact' method, because it is based on the cumulative probabilities of the binomial distribution (i.e., exactly the correct distribution rather than an approximation). However, in cases where we know the population size, the intervals may not be the smallest possible. For instance, for a population of size 20 with true proportion of 50%, Clopper–Pearson gives [0.272, 0.728], which has width 0.456 (and where bounds are 0.0280 away from the "next achievable values" of 6/20 and 14/20); whereas Wilson's gives [0.299, 0.701], which has width 0.401 (and is 0.0007 away from the next achievable values).
The Clopper–Pearson interval can be written as

or equivalently,

with

where 0 ≤ x ≤ n is the number of successes observed in the sample and Bin(n; θ) is a binomial random variable with n trials and probability of success θ.
Equivalently we can say that the Clopper–Pearson interval is with confidence level if is the infimum of those such that the following tests of hypothesis succeed with significance :



- H0: with HA:
- H0: with HA: .




Because of a relationship between the binomial distribution and the beta distribution, the Clopper–Pearson interval is sometimes presented in an alternate format that uses quantiles from the beta distribution.

where x is the number of successes, n is the number of trials, and B(p; v,w) is the pth quantile from a beta distribution with shape parameters v and w.
Thus, , where:



The binomial proportion confidence interval is then , as follows from the relation between the Binomial distribution cumulative distribution function and the regularized incomplete beta function.

When is either or , closed-form expressions for the interval bounds are available: when the interval is and when it is .[11]






The beta distribution is, in turn, related to the F-distribution so a third formulation of the Clopper–Pearson interval can be written using F quantiles:

where x is the number of successes, n is the number of trials, and F(c; d1, d2) is the c quantile from an F-distribution with d1 and d2 degrees of freedom.[12]
The Clopper–Pearson interval is an exact interval since it is based directly on the binomial distribution rather than any approximation to the binomial distribution. This interval never has less than the nominal coverage for any population proportion, but that means that it is usually conservative. For example, the true coverage rate of a 95% Clopper–Pearson interval may be well above 95%, depending on n and θ.[4] Thus the interval may be wider than it needs to be to achieve 95% confidence. In contrast, it is worth noting that other confidence bounds may be narrower than their nominal confidence width, i.e., the normal approximation (or "standard") interval, Wilson interval,[7] Agresti–Coull interval,[12] etc., with a nominal coverage of 95% may in fact cover less than 95%.[4]
The definition of the Clopper–Pearson interval can also be modified to obtain exact confidence intervals for different distributions. For instance, it can also be applied to the case where the samples are drawn without replacement from a population of a known size, instead of repeated draws of a binomial distribution. In this case, the underlying distribution would be the hypergeometric distribution.
Agresti–Coull interval
The Agresti–Coull interval is also another approximate binomial confidence interval.[12]
Given successes in trials, define


and

Then, a confidence interval for is given by


where is the quantile of a standard normal distribution, as before (for example, a 95% confidence interval requires , thereby producing ). According to Brown, Cai, and DasGupta,[4] taking instead of 1.96 produces the "add 2 successes and 2 failures" interval previously described by Agresti and Coull.[12]



This interval can be summarised as employing the centre-point adjustment, , of the Wilson score interval, and then applying the Normal approximation to this point.[3][4]


Arcsine transformation
The arcsine transformation has the effect of pulling out the ends of the distribution.[13] While it can stabilize the variance (and thus confidence intervals) of proportion data, its use has been criticized in several contexts.[14]
Let X be the number of successes in n trials and let p = X/n. The variance of p is

Using the arc sine transform the variance of the arcsine of p1/2 is[15]

So, the confidence interval itself has the following form:

where is the quantile of a standard normal distribution.

This method may be used to estimate the variance of p but its use is problematic when p is close to 0 or 1.
ta transform
Let p be the proportion of successes. For 0 ≤ a ≤ 2,

This family is a generalisation of the logit transform which is a special case with a = 1 and can be used to transform a proportional data distribution to an approximately normal distribution. The parameter a has to be estimated for the data set.
Rule of three - for when no successes are observed
The rule of three is used to provide a simple way of stating an approximate 95% confidence interval for p, in the special case that no successes () have been observed.[16] The interval is (0,3/n).

By symmetry, one could expect for only successes (), the interval is (1 − 3/n,1).

Comparison of different intervals
There are several research papers that compare these and other confidence intervals for the binomial proportion.[3][2][17][18] Both Agresti and Coull (1998)[12] and Ross (2003)[19] point out that exact methods such as the Clopper–Pearson interval may not work as well as certain approximations. The Normal approximation interval and its presentation in textbooks has been heavily criticised, with many statisticians advocating that it be not used.[4] The principal problems are overshoot (bounds exceed [0, 1]), zero-width intervals at = 0 and 1 (falsely implying certainty),[2] and overall inconsistency with significance testing.[3]
Of the approximations listed above, Wilson score interval methods (with or without continuity correction) have been shown to be the most accurate and the most robust,[3][4][2] though some prefer the Agresti–Coull approach for larger sample sizes.[4] Wilson and Clopper-Pearson methods obtain consistent results with source significance tests,[8] and this property is decisive for many researchers.
Many of these intervals can be calculated in R using packages like "binom", or in Python using package "ebcic" (Exact Binomial Confidence Interval Calculator).
See also
References
- Sullivan, Lisa (2017-10-27). "Confidence Intervals". Boston University School of Public Health.
- Newcombe, R. G. (1998). "Two-sided confidence intervals for the single proportion: comparison of seven methods". Statistics in Medicine. 17 (8): 857–872. doi:10.1002/(SICI)1097-0258(19980430)17:8<857::AID-SIM777>3.0.CO;2-E. PMID 9595616.
- Wallis, Sean A. (2013). "Binomial confidence intervals and contingency tests: mathematical fundamentals and the evaluation of alternative methods" (PDF). Journal of Quantitative Linguistics. 20 (3): 178–208. doi:10.1080/09296174.2013.799918. S2CID 16741749.
- Brown, Lawrence D.; Cai, T. Tony; DasGupta, Anirban (2001). "Interval Estimation for a Binomial Proportion". Statistical Science. 16 (2): 101–133. CiteSeerX 10.1.1.50.3025. doi:10.1214/ss/1009213286. MR 1861069. Zbl 1059.62533.
- Laplace, Pierre Simon (1812). Théorie analytique des probabilités (in French). Ve. Courcier. p. 283.
- How to calculate the standard error of a proportion using weighted data?
- Wilson, E. B. (1927). "Probable inference, the law of succession, and statistical inference". Journal of the American Statistical Association. 22 (158): 209–212. doi:10.1080/01621459.1927.10502953. JSTOR 2276774.
- Wallis, Sean A. (2021). Statistics in Corpus Linguistics - a new approach. New York: Routledge. ISBN 9781138589384.
- Cai, TT (2005). "One-sided confidence intervals in discrete distributions". Journal of Statistical Planning and Inference. 131 (1): 63–88. doi:10.1016/j.jspi.2004.01.005.
- Clopper, C.; Pearson, E. S. (1934). "The use of confidence or fiducial limits illustrated in the case of the binomial". Biometrika. 26 (4): 404–413. doi:10.1093/biomet/26.4.404.
- Thulin, Måns (2014-01-01). "The cost of using exact confidence intervals for a binomial proportion". Electronic Journal of Statistics. 8 (1): 817–840. arXiv:1303.1288. doi:10.1214/14-EJS909. ISSN 1935-7524. S2CID 88519382.
- Agresti, Alan; Coull, Brent A. (1998). "Approximate is better than 'exact' for interval estimation of binomial proportions". The American Statistician. 52 (2): 119–126. doi:10.2307/2685469. JSTOR 2685469. MR 1628435.
- Holland, Steven. "Transformations of proportions and percentages". strata.uga.edu. Retrieved 2020-09-08.
- Warton, David I.; Hui, Francis K. C. (January 2011). "The arcsine is asinine: the analysis of proportions in ecology". Ecology. 92 (1): 3–10. doi:10.1890/10-0340.1. hdl:1885/152287. ISSN 0012-9658.
- Shao J (1998) Mathematical statistics. Springer. New York, New York, USA
- Steve Simon (2010) "Confidence interval with zero events", The Children's Mercy Hospital, Kansas City, Mo. (website: "Ask Professor Mean at Stats topics or Medical Research Archived October 15, 2011, at the Wayback Machine)
- Reiczigel, J (2003). "Confidence intervals for the binomial parameter: some new considerations" (PDF). Statistics in Medicine. 22 (4): 611–621. doi:10.1002/sim.1320. PMID 12590417.
- Sauro J., Lewis J.R. (2005) "Comparison of Wald, Adj-Wald, Exact and Wilson intervals Calculator" Archived 2012-06-18 at the Wayback Machine. Proceedings of the Human Factors and Ergonomics Society, 49th Annual Meeting (HFES 2005), Orlando, FL, pp. 2100–2104
- Ross, T. D. (2003). "Accurate confidence intervals for binomial proportion and Poisson rate estimation". Computers in Biology and Medicine. 33 (6): 509–531. doi:10.1016/S0010-4825(03)00019-2. PMID 12878234.