Code folding
Code folding is a feature of some text editors, source code editors, and IDEs that allows the user to selectively hide and display – "fold" – sections of a currently edited file as a part of routine edit operations. This allows the user to manage large amounts of text while viewing only those subsections of the text that are specifically relevant at any given time.
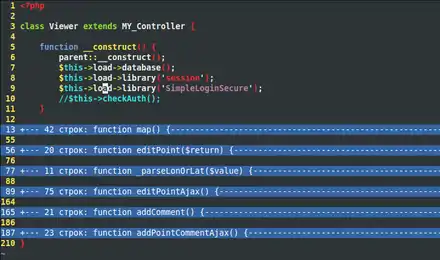
Identification of folds can be automatic, most often based on the syntax of the computer language in question, indentation, or manual, either based on an in-band marker (saved as part of the source code) or specified out-of-band, only within the editor.
Many editors provide disclosure widgets for code folding in a sidebar, next to line numbers, indicated for example by a triangle that points sideways (if collapsed) or down (if expanded), or by a [-] box for collapsible (expanded) text, and a [+] box for expandable (collapsed) text. This feature is commonly used by some computer programmers to manage source code files, and is also frequently used in data comparison, to only view the changed text.
Text folding is a similar feature used in folding editors, outliners, and some word processors, but is used for ordinary text and, if automatic, is based on syntax of human languages, particularly paragraphs, or section levels, rather than syntax of a computer language. Another variant of code folding is "data folding", which is implemented in some hex editors and is used to structure a binary file or hide inaccessible data sections in a RAM editor.[1] There are various alternative terms for such features, including "expand and collapse", "code hiding", and "outlining". In Microsoft word, the feature is called "collapsible outlining".
History
The earliest known example of code folding in an editor is in NLS (computer system).[2] Probably the first widely available folding editor was the 1974 Structured Programming Facility (SPF) editor for IBM 370 mainframes, which could hide lines based on their indentation. It displayed on character-mapped 3270 terminals.[3] It was very useful for prolix languages like COBOL. It evolved into the Interactive System Productivity Facility (ISPF).
Use
Code folding has various use patterns, primarily organizing code or hiding less useful information so one can focus on more important information. Common patterns follow.[4]
Outlining
Most basically, applications use code folding to outline source code, collapsing each block to a single line. This can be only top-level blocks like functions and classes, nested blocks like nested functions and methods, or all blocks, notably control-flow blocks. This allows one to get an overview of code, easily navigating and rearranging it, and to drill down into more detail as needed, without being distracted by other code. Viewing-wise, this allows one to quickly see a list of all functions (without their bodies), while navigation-wise this replaces extensive paging past long functions – or searching for the target – with going directly to the next function.
Hiding boilerplate code
Some languages or libraries require extensive boilerplate code. This results in extremely long code, which can obscure the main point. Further, substantive code can be lost in the boilerplate.
For example, in Java a single private field with a getter and setter requires at least 3 lines, if each is on a separate line:
private String name = null;
public String getName() { return name; }
public void setName(String name) { this.name = name; }
This expands to 10 lines with conventional function line breaks and spacing between functions (including trailing newline):
private String name = null;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
Documentation with Javadoc expands this to 20 lines:
/**
* Property <code>name</code> readable/writable.
*/
private String name = null;
/**
* Getter for property <code>name</code>
*/
public String getName() {
return name;
}
/**
* Setter for property <code>name</code>.
* @param name
*/
public void setName(String name) {
this.name = name;
}
If there are many such fields, the result can easily be hundreds of lines of code with very little "interesting" content – code folding can reduce this to a single line per field, or even to a single line for all fields. Further, if all routine fields are folded, but non-routine fields (where getter or setter is not just returning or assigning a private field) are not folded, it becomes easier to see the substantive code.
Collapsing metadata
Metadata can be lengthy, and is generally less important than the data it is describing. Collapsing metadata allows one to primarily focus on the data, not the metadata. For example, a long list of attributes in C# may be manually collapsed as follows:[5]
#region Attributes
[Browsable(false)]
[MergableProperty(false)]
[DefaultValue(null)]
[PersistenceMode(PersistenceMode.InnerProperty)]
[TemplateContainer(typeof(MyType))]
[TemplateInstance(TemplateInstance.Single)]
#endregion
public ITemplate ContentTemplate
{
get { return _temp; }
set { _temp = value; }
}
The resulting code displays as:
Attributes
public ITemplate ContentTemplate
{
get { return _temp; }
set { _temp = value; }
}
Collapsing comments
Comments are a form of human-readable metadata, and lengthy comments can disrupt the flow of code. This can be the case either for a long comment for a short section of code, such as a paragraph to explain one line, or comments for documentation generators, such as Javadoc or XML Documentation. Code folding allows one to have long comments, but to display them only when required. In cases where a long comment has a single summary line, such as Python docstrings, the summary can still be displayed when the section is collapsed, allowing a summary/detailed view.
Showing structure or sandwich code in structured programming
Structured programming consists of nested blocks of code, and long blocks of code – such as long switch statements – can obscure the overall structure. Code folding allows one to see the overall structure and expand to a specific level. Further, in some uses, particularly strict structured programming (single function exit), there are code patterns that are hard to see when looking at expanded code. For example, in resource management in structured programming, one generally acquires a resource, followed by a block of code using the resource, and finishing with releasing the resource. The acquisition/release pairing is hard to see if there is a long block of code in between, but easy to see if the intervening block is folded. Similarly, in conditional code like if...then...else, secondary blocks may be far from the condition statement.
Grouping code
Fold groups can be used to group code, either by explicit grouping – similar to comment blocks separating a module into sections, or class members into associated groups – or implicitly, such as by automatically grouping class members by access level.
Hiding legacy code
Legacy code – or any code that a developer does not wish to view or change at a given point in time – can be folded away so that programmers can concentrate on the code under consideration.
Conventions
In order to support code folding, the text editor must provide a mechanism for identifying "folding points" within a text file. Some text editors provide this mechanism automatically, while others provide defaults that can either be overridden or augmented by the user.
There are various mechanisms, coarsely divided as automatic and manual – do they require any specification by the programmer? Folding points are usually determined with one or more of the following mechanisms. Each of these has its own distinct advantages and difficulties, and it is essentially up to the developers who create the text editor software to decide which to implement. Text editors that provide support for multiple folding mechanisms typically allow the user to choose which is most appropriate for the file being edited.
Syntax-dependent
Syntax-dependent folding points are those that rely on the content of the file being edited in order to specify where specific folding regions should begin and end. Syntax-based folding points are typically defined around any or all of the standard sub-features of the markup language or programming language in use. These are desirable due to being automatic and agreeing with code structure, but may require significant work to implement, and time to compute when editing a file.
Indentation-based
Indentation-based folding points are generally specified by the position and sequence of non-printing whitespace, such as tabs and spaces, within the text. This is most often used as a simple form of syntax-based folding, as indentation almost always reflects nesting level in indent styles for structured programming languages.
This convention is particularly suitable to syntaxes that have an off-side rule, so the structure largely agrees with the indent. Examples include Python and text files that require indentation as a rule by themselves. However, even in these cases, structure does not exactly agree with indent, such as in line continuation, and thus syntax-dependent folding is preferred.
Token-based
Token-based folding points are specified using special delimiters that serve no other purpose in the text than to identify the boundaries of folding points. This convention can be compared to indentation-based folding points, where printable characters are used instead of whitespace. The most common delimiter tokens are {{{to begin the folded section, and}}} to end it.
Another notable token is #region (C# directives), respectively #Region (Visual Basic directives), used in Microsoft Visual Studio Code Editor. These are treated syntactically as compiler directives, though they do not affect compilation.
As a manual method, token-based folding allows discretion in grouping code based on arbitrary criteria, such as "functions related to a given task", which cannot be inferred from syntactic analysis.
Token-based folding requires in-band signalling, with folding tokens essentially being structured comments, and unlike other methods, are present in the source code and visible to other programmers. This allows them to be shared, but also requires their use (or preservation) by all programmers working on a particular file, and can cause friction and maintenance burden.
User-specified
User-specified folding allows the user to fold sections of text using a generic selection method, but without changing the source code (out-of-band), instead being specified only in the editor. For example, a programmer may select some lines of text and specify that they should be folded. Folded text might be anonymous or named, and this may be preserved across editing sessions or discarded. Unlike token-based folding, this does not change the source text – it thus is not shared with other editors of the file, and is not visible in the code.
Examples
The following document contains folding tokens ({{{ ... }}}):
Heading 1
{{{
Body
}}}
Heading 2
{{{
Body
}}}
Heading 3
{{{
Body
}}}
When loaded into a folding editor, the outline structure will be shown:
Heading 1
{{{ ...
Heading 2
{{{ ...
Heading 3
{{{ ...
Usually clicking on the {{{ marks makes the appropriate body text appear.
Software with code folding capability
One of the earliest folding editors was STET, an editor written for the VM/CMS operating system in 1977 by Mike Cowlishaw. STET is a text editor (for documentation, programs, etc.) which folds files on the basis of blocks of lines; any block of lines can be folded and replaced by a name line (which in turn can be part of a block which itself can then be folded).
A folding editor appeared in the occam IDE circa 1983, which was called the Inmos Transputer Development System (TDS)[6],.[7] The "f" editor (in list below) probably is the most intact legacy from this work.
The Macintosh computer historically had a number of source code editors that "folded" portions of code via "disclosure triangles". The UserLand Software product Frontier is a scripting environment that has this capability.[8]
Folding is provided by many modern text editors, and syntax-based or semantics-based folding is now a component of many software development environments. Editors include:
| Name | Token | Indentation | Syntax | User |
|---|---|---|---|---|
| ABAP Editor | Yes | ? | Yes | ? |
| AkelPad | ? | ? | Yes | ? |
| Anjuta IDE | ? | Yes | Yes | ? |
| Atom[lower-alpha 1] | ? | Yes | ? | Yes |
| BBEdit | ? | ? | Yes | ? |
| Brackets | Plug-in | Yes | Yes | No |
| Codeanywhere | Yes | Yes | Yes | ? |
| Codenvy | Yes | Yes | Yes | ? |
| Code::Blocks IDE | Yes | Yes | Yes | Yes |
| CudaText | ? | ? | ? | ? |
| Delphi IDE | Yes | ? | Yes | ? |
| Dreamweaver | ? | ? | ? | Yes |
| Eclipse | ? | ? | Yes | ? |
| EditPlus | No | Yes | No | No |
| Emacs | Yes[lower-alpha 2] | ?[lower-alpha 3] | Yes[lower-alpha 4] | Yes[lower-alpha 5] |
| EmEditor Professional | ? | Yes | Yes | ? |
| FlashDevelop IDE | ? | ? | Yes | ? |
| geany | ? | ? | Yes | ? |
| gedit | Yes | Yes | Yes | ? |
| ISPF | ? | Yes | ? | Yes |
| JED | Yes | Yes[lower-alpha 6] | ? | No |
| jEdit | Yes | Yes | Yes | Yes |
| Kate | Yes | Yes | Yes | Yes |
| MATLAB | No | No | Yes | No |
| MS Visual Studio | Yes | Yes | Yes | Yes |
| NetBeans IDE | Yes | Yes | Yes | Yes |
| Notepad++ | ? | Yes | Yes | Yes |
| NuSphere PHPEd | ? | ? | Yes | Yes |
| Qt Creator | ? | ? | Yes | ? |
| SciTE | Yes | Yes | Yes | ? |
| STET[lower-alpha 7] | ? | ? | ? | ? |
| TextMate | Yes | Yes | Yes | Yes |
| UltraEdit | No | No | Yes | Yes |
| Vim | Yes | Yes | Yes | Yes |
| Visual Expert | ? | ? | Yes | ? |
| Visual Studio Code | Yes | Yes | Yes | No |
| Xcode | Yes | Yes | Yes | Yes |
| Zend Studio | ? | ? | ? | ? |
Other editors
- aoeui, the Dvorak-optimized editor
- Author-it enterprise authoring and component content management software
- Bluefish
- Delphi
- Emacs
- f (alias xf, Winf, Winf32)
- Folding Text Editor
- GFA BASIC
- GridinSoft Notepad
- IntelliJ IDEA (and other JetBrains' IDE)
- Keynote
- Komodo Edit
- Kwrite
- Leo
- LEXX/LPEX (editor for the OED)[9]
- MonoDevelop
- NoteTab Pro
- Padre
- RJ Text Editor
- Smultron
- The Hessling Editor
- Visual Studio
- WinShell (since version 3.30)
- XEDIT (however its folding is effected by scripts)
- Zeus
Notes
- http://flight-manual.atom.io/using-atom/sections/folding/
- Token-based folding is implemented by the folding minor mode. One can also use outline and allout minor modes for sectioning program sources.
- One can use the
set-selective-displayfunction in Emacs to hide lines based on the indentation level, as suggested in the Universal code folding note. - Syntax-dependent folding is supported by the outline and allout modes
for special dedicated outline-syntaxes; by the hideshow minor mode for some programming languages; also, by the semantic-tag-folding minor mode and the
senator-fold-tagcommand for syntaxes supported by semantic (a component of CEDET), as well as by doc-mode for JavaDoc or Doxygen comments, by TeX-fold-mode,sgml-fold-elementcommand, nxml-outln library in the corresponding language-specific modes, and possibly in other modes for particular syntaxes. Sometimes, the standard simple outline minor mode is used to simulate syntax-based folding, cf. the use of it in properly indented Emacs Lisp source code, the use of it (see near the end of the page) for properly indented HTML. Several folding mechanisms are unified by the fold-dwim interface. See also CategoryHideStuff. - Folding of user-selected regions in Emacs is implemented by the
hide-region-hidecommand. - The
set_selective_displayfunction may be used to hide lines indented beyond a specified amount. - STET may have been the first text editor that supported folding
See also
- The Programming features section of the Comparison of text editors article for more editors that support folding
References
- "Data folding in HxD hex editor (listed as feature of RAM-Editor)". Retrieved 2007-04-30.
- The Mother of All Demos, presented by Douglas Engelbart (1968), retrieved 2019-12-29
- "History of ISPF". Retrieved 2015-10-27.
- Atwood 2008.
- Post #31, Rob, July 2008
- North American Transputer Users Group. Conference (2nd : 1989 : Durham, N.C.) (1990). Transputer research and applications, 2 : NATUG-2, proceedings of the Second Conference of the North American Transputer Users Group, October 18-19, 1989, Durham, NC. Board, John A., Duke University. Amsterdam: IOS Press. p. 85. ISBN 9051990278. OCLC 35478471.
- Cormie, David (1986). "INMOS Technical Note 03 - Getting started with the TDS" (PDF). transputer.net. Retrieved 2019-07-19.
- "Outliners.com". Archived from the original on 2006-12-23. Retrieved 2006-12-27.
- LEXX – A programmable structured editor IBM Journal of Research and Development, Vol 31, No. 1, 1987, IBM Reprint order number G322-0151
- Atwood, Jeff (6 Jul 2008). "The Problem With Code Folding". Coding Horror– criticism of code folding, detailed comments on use.
External links
- What is a folding editor? by the author of the
feeditor. - Description of the folding editor used in occam.