Kernel principal component analysis
In the field of multivariate statistics, kernel principal component analysis (kernel PCA)[1] is an extension of principal component analysis (PCA) using techniques of kernel methods. Using a kernel, the originally linear operations of PCA are performed in a reproducing kernel Hilbert space.
Background: Linear PCA
Recall that conventional PCA operates on zero-centered data; that is,
- ,

where is the vector of one of the multivariate observations. It operates by diagonalizing the covariance matrix,



in other words, it gives an eigendecomposition of the covariance matrix:

which can be rewritten as
- .[2]

(See also: Covariance matrix as a linear operator)
Introduction of the Kernel to PCA
To understand the utility of kernel PCA, particularly for clustering, observe that, while N points cannot, in general, be linearly separated in dimensions, they can almost always be linearly separated in dimensions. That is, given N points, , if we map them to an N-dimensional space with


- where ,


it is easy to construct a hyperplane that divides the points into arbitrary clusters. Of course, this creates linearly independent vectors, so there is no covariance on which to perform eigendecomposition explicitly as we would in linear PCA.

Instead, in kernel PCA, a non-trivial, arbitrary function is 'chosen' that is never calculated explicitly, allowing the possibility to use very-high-dimensional 's if we never have to actually evaluate the data in that space. Since we generally try to avoid working in the -space, which we will call the 'feature space', we can create the N-by-N kernel

which represents the inner product space (see Gramian matrix) of the otherwise intractable feature space. The dual form that arises in the creation of a kernel allows us to mathematically formulate a version of PCA in which we never actually solve the eigenvectors and eigenvalues of the covariance matrix in the -space (see Kernel trick). The N-elements in each column of K represent the dot product of one point of the transformed data with respect to all the transformed points (N points). Some well-known kernels are shown in the example below.

Because we are never working directly in the feature space, the kernel-formulation of PCA is restricted in that it computes not the principal components themselves, but the projections of our data onto those components. To evaluate the projection from a point in the feature space onto the kth principal component (where superscript k means the component k, not powers of k)


We note that denotes dot product, which is simply the elements of the kernel . It seems all that's left is to calculate and normalize the , which can be done by solving the eigenvector equation




where N is the number of data points in the set, and and are the eigenvalues and eigenvectors of K. Then to normalize the eigenvectors 's, we require that




Care must be taken regarding the fact that, whether or not has zero-mean in its original space, it is not guaranteed to be centered in the feature space (which we never compute explicitly). Since centered data is required to perform an effective principal component analysis, we 'centralize' K to become



where denotes a N-by-N matrix for which each element takes value . We use to perform the kernel PCA algorithm described above.


One caveat of kernel PCA should be illustrated here. In linear PCA, we can use the eigenvalues to rank the eigenvectors based on how much of the variation of the data is captured by each principal component. This is useful for data dimensionality reduction and it could also be applied to KPCA. However, in practice there are cases that all variations of the data are same. This is typically caused by a wrong choice of kernel scale.
Large datasets
In practice, a large data set leads to a large K, and storing K may become a problem. One way to deal with this is to perform clustering on the dataset, and populate the kernel with the means of those clusters. Since even this method may yield a relatively large K, it is common to compute only the top P eigenvalues and eigenvectors of the eigenvalues are calculated in this way.
Example
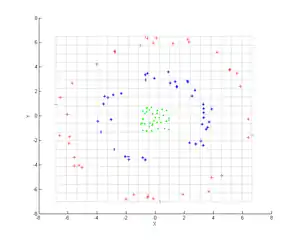
Consider three concentric clouds of points (shown); we wish to use kernel PCA to identify these groups. The color of the points does not represent information involved in the algorithm, but only shows how the transformation relocates the data points.
First, consider the kernel

Applying this to kernel PCA yields the next image.
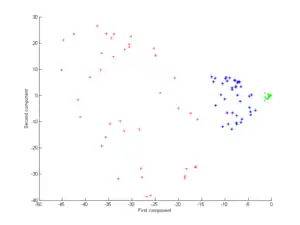
Now consider a Gaussian kernel:

That is, this kernel is a measure of closeness, equal to 1 when the points coincide and equal to 0 at infinity.

Note in particular that the first principal component is enough to distinguish the three different groups, which is impossible using only linear PCA, because linear PCA operates only in the given (in this case two-dimensional) space, in which these concentric point clouds are not linearly separable.
Applications
Kernel PCA has been demonstrated to be useful for novelty detection[3] and image de-noising.[4]
See also
References
- Schölkopf, Bernhard (1998). "Nonlinear Component Analysis as a Kernel Eigenvalue Problem". Neural Computation. 10 (5): 1299–1319. CiteSeerX 10.1.1.100.3636. doi:10.1162/089976698300017467. S2CID 6674407.
- Nonlinear Component Analysis as a Kernel Eigenvalue Problem (Technical Report)
- Hoffmann, Heiko (2007). "Kernel PCA for Novelty Detection". Pattern Recognition. 40 (3): 863–874. doi:10.1016/j.patcog.2006.07.009.
- Kernel PCA and De-Noising in Feature Spaces. NIPS, 1999