Pandemonium architecture
Pandemonium architecture arose in response to the inability of template matching theories to offer a biologically plausible explanation of the image constancy phenomena. Contemporary researchers praise this architecture for its elegancy and creativity; that the idea of having multiple independent systems (e.g., feature detectors) working in parallel to address the image constancy phenomena of pattern recognition is powerful yet simple. The basic idea of the pandemonium architecture is that a pattern is first perceived in its parts before the "whole".[1]
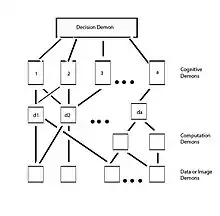
Pandemonium architecture was one of the first computational models in pattern recognition. Although not perfect, the pandemonium architecture influenced the development of modern connectionist, artificial intelligence, and word recognition models.[2]
History

Most research in perception has been focused on the visual system, investigating the mechanisms of how we see and understand objects. A critical function of our visual system is its ability to recognize patterns, but the mechanism by which this is achieved is unclear.[3]
The earliest theory that attempted to explain how we recognize patterns is the template matching model. According to this model, we compare all external stimuli against an internal mental representation. If there is "sufficient" overlap between the perceived stimulus and the internal representation, we will "recognize" the stimulus. Although some machines follow a template matching model (e.g., bank machines verifying signatures and accounting numbers), the theory is critically flawed in explaining the phenomena of image constancy: we can easily recognize a stimulus regardless of the changes in its form of presentation (e.g., T and T are both easily recognized as the letter T). It is highly unlikely that we have a stored template for all of the variations of every single pattern.[4]
As a result of the biological plausibility criticism of the template matching model, feature detection models begun to rise. In a feature detection model, the image is first perceived in its basic individual elements before it is recognized as a whole object. For example, when we are presented with the letter A, we would first see a short horizontal line and two slanted long diagonal lines. Then we would combine the features to complete the perception of A. Each unique pattern consists of different combination of features, which means those that are formed with the same features will generate the same recognition. That is, regardless of how we rotate the letter A, is still perceived as the letter A. It is easy for this sort of architecture to account for the image constancy phenomena because you only need to "match" at the basic featural level, which is presumed to be limited and finite, thus biologically plausible. The best known feature detection model is called the pandemonium architecture.[4]
Pandemonium architecture
The pandemonium architecture was originally developed by Oliver Selfridge in the late 1950s. The architecture is composed of different groups of "demons" working independently to process the visual stimulus. Each group of demons is assigned to a specific stage in recognition, and within each group, the demons work in parallel. There are four major groups of demons in the original architecture.[3]
| Stage |
Demon name | Function |
|---|---|---|
| 1 | Image demon | Records the image that is received in the retina. |
| 2 | Feature demons | There are many feature demons, each representing a specific feature. For example, there is a feature demon for short straight lines, another for curved lines, and so forth. Each feature demon's job is to "yell" if they detect a feature that they correspond to. Note that, feature demons are not meant to represent any specific neurons, but to represent a group of neurons that have similar functions. For example, the vertical line feature demon is used to represent the neurons that respond to the vertical lines in the retina image. |
| 3 | Cognitive demons | Watch the "yelling" from the feature demons. Each cognitive demon is responsible for a specific pattern (e.g., a letter in the alphabet). The "yelling" of the cognitive demons is based on how much of their pattern was detected by the feature demons. The more features the cognitive demons find that correspond to their pattern, the louder they "yell". For example, if the curved, long straight and short angled line feature demons are yelling really loud, the R letter cognitive demon might get really excited, and the P letter cognitive demon might be somewhat excited as well; but the Z letter cognitive demon is very likely to be quiet. |
| 4 | Decision demon | Represents the final stage of processing. It listens to the "yelling" produced by the cognitive demons. It selects the loudest cognitive demon. The demon that gets selected becomes our conscious perception. Continuing with our previous example, the R cognitive demon would be the loudest, seconded by P; therefore we will perceive R, but if we were to make a mistake because of poor displaying conditions (e.g., letters are quickly flashed or have parts occluded), it is likely to be P. Note that, the "pandemonium" simply represents the cumulative "yelling" produced by the system. |
The concept of feature demons, that there are specific neurons dedicated to perform specialized processing is supported by research in neuroscience. Hubel and Wiesel found there were specific cells in a cat's brain that responded to specific lengths and orientations of a line. Similar findings were discovered in frogs, octopuses and a variety of other animals. Octopuses were discovered to be only sensitive to verticality of lines, whereas frogs demonstrated a wider range of sensitivity. These animal experiments demonstrate that feature detectors seem to be a very primitive development. That is, it did not result from the higher cognitive development of humans. Not surprisingly, there is also evidence that the human brain possesses these elementary feature detectors as well.[5][6][7]
Moreover, this architecture is capable of learning, similar to a back-propagation styled neural network. The weight between the cognitive and feature demons can be adjusted in proportion to the difference between the correct pattern and the activation from the cognitive demons. To continue with our previous example, when we first learned the letter R, we know is composed of a curved, long straight, and a short angled line. Thus when we perceive those features, we perceive R. However, the letter P consists of very similar features, so during the beginning stages of learning, it is likely for this architecture to mistakenly identify R as P. But through constant exposure of confirming R's features to be identified as R, the weights of R's features to P are adjusted so the P response becomes inhibited (e.g., learning to inhibit the P response when a short angled line is detected). In principle, a pandemonium architecture can recognize any pattern.[8]
As mentioned earlier, this architecture makes error predictions based on the amount of overlapping features. Such as, the most likely error for R should be P. Thus, in order to show this architecture represents the human pattern recognition system we must put these predictions into test. Researchers have constructed scenarios where various letters are presented in situations that make them difficult to identify; then types of errors were observed, which was used to generate confusion matrices: where all of the errors for each letter are recorded. Generally, the results from these experiments matched the error predictions from the pandemonium architecture. Also as a result of these experiments, some researchers have proposed models that attempted to list all of the basic features in the Roman alphabet.[9][10][11][12]
Criticism
A major criticism of the pandemonium architecture is that it adopts a completely bottom-up processing: recognition is entirely driven by the physical characteristics of the targeted stimulus. This means that it is unable to account for any top-down processing effects, such as context effects (e.g., pareidolia), where contextual cues can facilitate (e.g., word superiority effect: it is relatively easier to identify a letter when it is part of a word than in isolation) processing. However, this is not a fatal criticism to the overall architecture, because is relatively easy to add a group of contextual demons to work along with the cognitive demons to account for these context effects.[13]
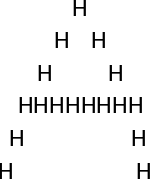
Although the pandemonium architecture is built on the fact that it can account for the image constancy phenomena, some researchers have argued otherwise; and pointed out that the pandemonium architecture might share the same flaws from the template matching models. For example, the letter H is composed of 2 long vertical lines and a short horizontal line; but if we rotate the H 90 degrees in either direction, it is now composed of 2 long horizontal lines and a short vertical line. In order to recognize the rotated H as H, we would need a rotated H cognitive demon. Thus we might end up with a system that requires a large amount of cognitive demons in order to produce accurate recognition, which would lead to the same biological plausibility criticism of the template matching models. However, it is rather difficult to judge the validity of this criticism because the pandemonium architecture does not specify how and what features are extracted from incoming sensory information, it simply outlines the possible stages of pattern recognition. But of course that raises its own questions, to which it is almost impossible to criticize such a model if it does not include specific parameters. Also, the theory appears to be rather incomplete without defining how and what features are extracted, which proves to be especially problematic with complex patterns (e.g., extracting the weight and features of a dog).[3][14]
Some researchers have also pointed out that the evidence supporting the pandemonium architecture has been very narrow in its methodology. Majority of the research that supports this architecture has often referred to its ability to recognize simple schematic drawings that are selected from a small finite set (e.g., letters in the Roman alphabet). Evidence from these types of experiments can lead to overgeneralized and misleading conclusions, because the recognition process of complex, three-dimensional patterns could be very different from simple schematics. Furthermore, some have criticized the methodology used in generating the confusion matrix, because it confounds perceptual confusion (error in identification caused by overlapping features between the error and the correct answer) with post-perceptual guessing (people randomly guessing because they cannot be sure what they saw). However, these criticisms were somewhat addressed when similar results were replicated with other paradigms (e.g., go/no go and same-different tasks), supporting the claim that humans do have elementary feature detectors. These new paradigms relied on reaction time as the dependent variable, which also avoided the problem of empty cells that is inherent with the confusion matrix (statistical analyses are difficult to conduct and interpret when the data have empty cells).[7]
Additionally, some researchers have pointed out that feature accumulation theories like the pandemonium architecture have the processing stages of pattern recognition almost backwards. This criticism was mainly used by advocates of the global-to-local theory, who argued and provided evidence that perception begins with a blurry view of the whole that refines overtime, implying feature extraction does not happen in the early stages of recognition.[15] However, there is nothing to prevent a demon from recognizing a global pattern in parallel with other demons recognizing local patterns within the global pattern.
Applications and influences

The pandemonium architecture has been applied to solve several real-world problems, such as translating hand-sent Morse codes and identifying hand-printed letters. The overall accuracy of pandemonium-based models are impressive, even when the system was given a short learning period. For example, Doyle constructed a pandemonium-based system with over 30 complex feature-analyzers. He then fed his system several hundred letters for learning. During this phase, the system analyzed the inputted letter and generated its own output (what the system identifies the letter as). The output from the system was compared against the correct identification, which sends an error signal back to the system to adjust the weights between the features analyzers accordingly. In the testing phase, unfamiliar letters were presented (different style and size of the letters than those that were presented in the learning phase), and the system was able to achieve a near 90% accuracy. Because of its impressive capability to recognize words, all modern theories on how humans read and recognize words follow this hierarchal structure: word recognition begins with feature extractions of the letters, which then activates the letter detectors[16] (e.g., SOLAR,[17] SERIOL,[18] IA,[19] DRC[20]).
Based on the original pandemonium architecture, John Jackson has extended the theory to explain phenomena beyond perception. Jackson offered the analogy of an arena to account for "consciousness". His arena consisted of a stand, a playing field, and a sub-arena. The arena was populated by a multitude of demons. The demons that were designated in the playing fields were the active demons, as they represent the active elements of human consciousness. The demons in the stands are to watch those in the playing field until something excites them; each demon is excited by different things. The more excited the demons get, the louder they yell. If a demon yells pass a set threshold, it gets to join the other demons in the playing field and perform its function, which may then excite other demons, and this cycle continues. The sub-arena in the analogy functions as the learning and feedback mechanism of the system. The learning system here is similar to any other neural styled networks, which is through modifying the connection strength between the demons; in other words, how the demons respond to each other's yelling. This multiple agent approach to human information processing became the assumption for many modern artificial intelligence systems.[21][22]
Comparisons
Comparison with template matching theories
Although the pandemonium architecture arose as a response to address a major criticism of the template matching theories, the two are actually rather similar in some sense: there is a process where a specific set of features for items is matched against some sort of mental representation. The critical difference between the two is that the image is directly compared against an internal representation in the template matching theories, whereas with the pandemonium architecture, the image is first diffused and processed at the featural level. This granted pandemonium architectures tremendous power because it is capable of recognizing a stimulus despite its changes in size, style and other transformations; without the presumption of an unlimited pattern memory. It is also unlikely that the template matching theories will function properly when faced with realistic visual inputs, where objects are presented in three dimensions and often occluded by other objects (e.g., half of a book is covered by a piece of paper, but we can still recognize it as a book with relative ease). Nonetheless, some researchers have conducted experiments comparing the two theories. Not surprisingly, the results often favored a hierarchal feature building model like the pandemonium architecture.[23][24][25]
Comparison with Hebbian pattern recognition
The Hebbian model resembles feature-oriented theories like the pandemonium architecture in many aspects. The first level of processing in the Hebbian model is called the cell assemblies, which have very similar functions to feature demons. However, cell assemblies are more limited than the feature demons, because it can only extracts lines, angles and contours. The cell assemblies are combined to form phase sequences, which is very similar to the function of the cognitive demons. In a sense, many consider the Hebbian model to be a crossover between the template and feature matching theories, as the features extracted from the Hebbian models can be considered as simple templates.[8]
See also
References
- Anderson, James A.; Rosenfeld, Edward (1988). Neurocomputing (2nd print ed.). Cambridge, Mass.: MIT Press. ISBN 978-0262010979.
- Gernsbacher, Morton Ann (1998). Handbook of psycholinguistics ([Nachdr.] ed.). San Diego, Calif. [u.a.]: Academic Press. ISBN 978-0-12-280890-6.
- Lindsay, Peter H.; Norman, Donald A. (1977). Human Information Processing (2nd ed.). New York: Academic Press. ISBN 978-0124509603.
- Friedenberg, Jay; Silverman, Gordon (2011-07-14). Cognitive Science: An introduction to the study of mind (2nd ed.). Thousand Oaks, Calif.: SAGE. ISBN 9781412977616.
- Sutherland, Stuart (1957). "Visual Discrimination of Shape by Octopus". British Journal of Psychology. 48 (1): 55–70. doi:10.1111/j.2044-8295.1957.tb00599.x. PMID 13413184.
- Lettvin, J.; Maturana, H.; McCulloch, W.; Pitts, W. (1 November 1959). "What the Frog's Eye Tells the Frog's Brain". Proceedings of the IRE. 47 (11): 1940–1951. doi:10.1109/JRPROC.1959.287207.
- Grainger, Jonathan; Rey, Arnaud; Dufau, Stéphane (1 October 2008). "Letter perception: from pixels to pandemonium". Trends in Cognitive Sciences. 12 (10): 381–387. doi:10.1016/j.tics.2008.06.006. PMID 18760658.
- Neisser, Ulric (1967). Cognitive Psychology. New York: Appleton-Century-Crofts.
Neisser, Ulric.
- Kinney, Glenn; Marsetta, Marion; Showman, Diana (1966). Studies of Display Symbol Legibility, Part XII: The legibility of alphanumeric symbols for digitalized television. Bedford, Mass: The Mitre Corporation.
- Gibson, Eleanor J. (1969). Principles of Perceptual Learning and Development. New York: Appleton-Century-Crofts. ISBN 9780390361455.
- Geyer, L. H.; DeWald, C. G. (1 October 1973). "Feature lists and confusion matrices". Perception & Psychophysics. 14 (3): 471–482. doi:10.3758/BF03211185.
- Keren, Gideon; Baggen, Stan (1 May 1981). "Recognition models of alphanumeric characters". Perception & Psychophysics. 29 (3): 234–246. doi:10.3758/BF03207290. PMID 7267275.
- Reicher, Gerald M. (1 January 1969). "Perceptual recognition as a function of meaningfulness of stimulus material". Journal of Experimental Psychology. 81 (2): 275–280. doi:10.1037/h0027768. PMID 5811803.
- Minsky, Marvin Lee; Papert, Seymour (1969). Perceptrons: An introduction to computational geometry (2nd print. with corr. ed.). Cambridge, Mass.: MIT Press. ISBN 978-0262630221.
- Lupker, Stephen J. (1 July 1979). "On the nature of perceptual information during letter perception". Perception & Psychophysics. 25 (4): 303–312. doi:10.3758/BF03198809. PMID 461090.
- Doyle, W (1960). Recognition of sloppy, hand-printed characters. San Francisco, California: Proc. West Joint Computer Conference.
- Davis, Colin J. (1 January 2010). "The spatial coding model of visual word identification". Psychological Review. 117 (3): 713–758. doi:10.1037/a0019738. PMID 20658851.
- Whitney, Carol (1 June 2001). "How the brain encodes the order of letters in a printed word: The SERIOL model and selective literature review". Psychonomic Bulletin & Review. 8 (2): 221–243. doi:10.3758/BF03196158. PMID 11495111.
- McClelland, James L.; Rumelhart, David E. (1 January 1981). "An interactive activation model of context effects in letter perception: I. An account of basic findings". Psychological Review. 88 (5): 375–407. doi:10.1037/0033-295X.88.5.375.
- Coltheart, Max; Rastle, Kathleen; Perry, Conrad; Langdon, Robyn; Ziegler, Johannes (1 January 2001). "DRC: A dual route cascaded model of visual word recognition and reading aloud". Psychological Review. 108 (1): 204–256. doi:10.1037/0033-295X.108.1.204. PMID 11212628.
- Jackson, John (July 1987). "Idea for a Mind". Sigart Newsletter.
- Ntuen, Celestine A.; Park, Eui H. (1996). Human interactions with complex systems: Conceptual principles and design practice. Springer. ISBN 978-0792397793.
- Gibson, J (May 1965). "Learning to Read". Science. 148 (3673): 1066–1072. Bibcode:1965Sci...148.1066G. doi:10.1126/science.148.3673.1066. PMID 14289608.
- Wheeler, Daniel D (1 January 1970). "Processes in word recognition". Cognitive Psychology. 1 (1): 59–85. doi:10.1016/0010-0285(70)90005-8. hdl:2027.42/32833.
- Larsen, Axel; Bundesen, Claus (1 March 1996). "A template-matching pandemonium recognizes unconstrained handwritten characters with high accuracy". Memory & Cognition. 24 (2): 136–143. doi:10.3758/BF03200876. PMID 8881318.