Regular tree grammar
In theoretical computer science and formal language theory, a regular tree grammar (RTG) is a formal grammar that describes a set of directed trees, or terms.[1] A regular word grammar can be seen as a special kind of regular tree grammar, describing a set of single-path trees.
Definition
A regular tree grammar G is defined by the tuple
G = (N, Σ, Z, P),
where
- N is a finite set of nonterminals,
- Σ is a ranked alphabet (i.e., an alphabet whose symbols have an associated arity) disjoint from N,
- Z is the starting nonterminal, with Z ∈ N, and
- P is a finite set of productions of the form A → t, with A ∈ N, and t ∈ TΣ(N), where TΣ(N) is the associated term algebra, i.e. the set of all trees composed from symbols in Σ ∪ N according to their arities, where nonterminals are considered nullary.
Derivation of trees
The grammar G implicitly defines a set of trees: any tree that can be derived from Z using the rule set P is said to be described by G. This set of trees is known as the language of G. More formally, the relation ⇒G on the set TΣ(N) is defined as follows:
A tree t1∈ TΣ(N) can be derived in a single step into a tree t2 ∈ TΣ(N) (in short: t1 ⇒G t2), if there is a context S and a production (A→t) ∈ P such that:
- t1 = S[A], and
- t2 = S[t].
Here, a context means a tree with exactly one hole in it; if S is such a context, S[t] denotes the result of filling the tree t into the hole of S.
The tree language generated by G is the language L(G) = { t ∈ TΣ | Z ⇒G* t }.
Here, TΣ denotes the set of all trees composed from symbols of Σ, while ⇒G* denotes successive applications of ⇒G.
A language generated by some regular tree grammar is called a regular tree language.
Examples
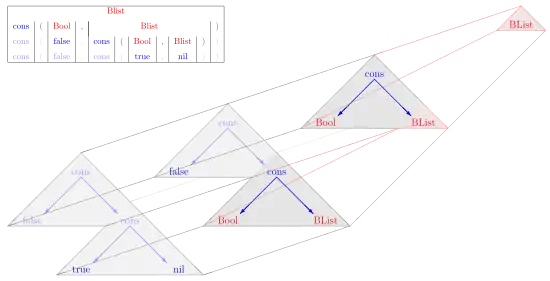
Let G1 = (N1,Σ1,Z1,P1), where
- N1 = {Bool, BList } is our set of nonterminals,
- Σ1 = { true, false, nil, cons(.,.) } is our ranked alphabet, arities indicated by dummy arguments (i.e. the symbol cons has arity 2),
- Z1 = BList is our starting nonterminal, and
- the set P1 consists of the following productions:
- Bool → false
- Bool → true
- BList → nil
- BList → cons(Bool,BList)
An example derivation from the grammar G1 is
BList ⇒ cons(Bool,BList) ⇒ cons(false,cons(Bool,BList)) ⇒ cons(false,cons(true,nil)).
The image shows the corresponding derivation tree; it is a tree of trees (main picture), whereas a derivation tree in word grammars is a tree of strings (upper left table).
The tree language generated by G1 is the set of all finite lists of boolean values, that is, L(G1) happens to equal TΣ1. The grammar G1 corresponds to the algebraic data type declarations (in the Standard ML programming language):
datatype Bool
= false
| true
datatype BList
= nil
| cons of Bool * BList
Every member of L(G1) corresponds to a Standard-ML value of type BList.
For another example, let G2 = (N1,Σ1,BList1,P1 ∪ P2), using the nonterminal set and the alphabet from above, but extending the production set by P2, consisting of the following productions:
- BList1 → cons(true,BList)
- BList1 → cons(false,BList1)
The language L(G2) is the set of all finite lists of boolean values that contain true at least once. The set L(G2) has no datatype counterpart in Standard ML, nor in any other functional language. It is a proper subset of L(G1). The above example term happens to be in L(G2), too, as the following derivation shows:
BList1 ⇒ cons(false,BList1) ⇒ cons(false,cons(true,BList)) ⇒ cons(false,cons(true,nil)).
Language properties
If L1, L2 both are regular tree languages, then the tree sets L1 ∩ L2, L1 ∪ L2, and L1 \ L2 are also regular tree languages, and it is decidable whether L1 ⊆ L2, and whether L1 = L2.
Alternative characterizations and relation to other formal languages
- Regular tree grammars are a generalization of regular word grammars.
- The regular tree languages are also the languages recognized by bottom-up tree automata and nondeterministic top-down tree automata.[2]
- Rajeev Alur and Parthasarathy Madhusudan related a subclass of regular binary tree languages to nested words and visibly pushdown languages.[3][4]
Applications
Applications of regular tree grammars include:
- Instruction selection in compiler code generation[5]
- A decision procedure for the first-order logic theory of formulas over equality (=) and set membership (∈) as the only predicates[6]
- Solving constraints about mathematical sets[7]
- The set of all truths expressible in first-order logic about a finite algebra (which is always a regular tree language)[8]
- Graph-search [9]
See also
- Set constraint – a generalization of regular tree grammars
- Tree-adjoining grammar
References
- "Regular tree grammars as a formalism for scope underspecification". CiteSeerX 10.1.1.164.5484. Cite journal requires
|journal=(help) - Comon, Hubert; Dauchet, Max; Gilleron, Remi; Löding, Christof; Jacquemard, Florent; Lugiez, Denis; Tison, Sophie; Tommasi, Marc (12 October 2007). "Tree Automata Techniques and Applications". Retrieved 25 January 2016.
- Alur, R.; Madhusudan, P. (2004). "Visibly pushdown languages" (PDF). Proceedings of the thirty-sixth annual ACM symposium on Theory of computing - STOC '04. pp. 202–211. doi:10.1145/1007352.1007390. ISBN 978-1581138528. Sect.4, Theorem 5,
- Alur, R.; Madhusudan, P. (2009). "Adding nesting structure to words" (PDF). Journal of the ACM. 56 (3): 1–43. CiteSeerX 10.1.1.145.9971. doi:10.1145/1516512.1516518. Sect.7
- Emmelmann, Helmut (1991). "Code Selection by Regularly Controlled Term Rewriting". Code Generation - Concepts, Tools, Techniques. Workshops in Computing. Springer. pp. 3–29.
- Comon, Hubert (1990). "Equational Formulas in Order-Sorted Algebras". Proc. ICALP.
- Gilleron, R.; Tison, S.; Tommasi, M. (1993). "Solving Systems of Set Constraints using Tree Automata". 10th Annual Symposium on Theoretical Aspects of Computer Science. LNCS. 665. Springer. pp. 505–514.
- Burghardt, Jochen (2002). "Axiomatization of Finite Algebras". Advances in Artificial Intelligence. LNAI. 2479. Springer. pp. 222–234. arXiv:1403.7347. Bibcode:2014arXiv1403.7347B. ISBN 3-540-44185-9.
- Ziv-Ukelson, Smoly (2016). Algorithms for Regular Tree Grammar Network Search and Their Application to Mining Human–viral Infection Patterns. J. of Comp. Bio.
Further reading
- Regular tree grammars were already described in 1968 by:
- Brainerd, W.S. (1968). "The Minimalization of Tree Automata". Information and Control. 13 (5): 484–491. doi:10.1016/s0019-9958(68)90917-0.
- Thatcher, J.W.; Wright, J.B. (1968). "Generalized Finite Automata Theory with an Application to a Decision Problem of Second-Order Logic". Mathematical Systems Theory. 2 (1): 57–81. doi:10.1007/BF01691346.
- A book devoted to tree grammars is: Nivat, Maurice; Podelski, Andreas (1992). Tree Automata and Languages. Studies in Computer Science and Artificial Intelligence. 10. North-Holland.
- Algorithms on regular tree grammars are discussed from an efficiency-oriented view in: Aiken, A.; Murphy, B. (1991). "Implementing Regular Tree Expressions". ACM Conference on Functional Programming Languages and Computer Architecture. pp. 427–447. CiteSeerX 10.1.1.39.3766.
- Given a mapping from trees to weights, Donald Knuth's generalization of Dijkstra's shortest-path algorithm can be applied to a regular tree grammar to compute for each nonterminal the minimum weight of a derivable tree. Based on this information, it is straightforward to enumerate its language in increasing weight order. In particular, any nonterminal with infinite minimum weight produces the empty language. See: Knuth, D.E. (1977). "A Generalization of Dijkstra's Algorithm". Information Processing Letters. 6 (1): 1–5. doi:10.1016/0020-0190(77)90002-3.
- Regular tree automata have been generalized to admit equality tests between sibling nodes in trees. See: Bogaert, B.; Tison, Sophie (1992). "Equality and Disequality Constraints on Direct Subterms in Tree Automata". Proc. 9th STACS. LNCS. 577. Springer. pp. 161–172.
- Allowing equality tests between deeper nodes leads to undecidability. See: Tommasi, M. (1991). Automates d'Arbres avec Tests d'Égalités entre Cousins Germains. LIFL-IT.