Training, validation, and test sets
In machine learning, a common task is the study and construction of algorithms that can learn from and make predictions on data.[1] Such algorithms function by making data-driven predictions or decisions,[2] through building a mathematical model from input data.

The data used to build the final model usually comes from multiple datasets. In particular, three datasets are commonly used in different stages of the creation of the model.
The model is initially fit on a training dataset,[3] which is a set of examples used to fit the parameters (e.g. weights of connections between neurons in artificial neural networks) of the model.[4] The model (e.g. a neural net or a naive Bayes classifier) is trained on the training dataset using a supervised learning method, for example using optimization methods such as gradient descent or stochastic gradient descent. In practice, the training dataset often consists of pairs of an input vector (or scalar) and the corresponding output vector (or scalar), where the answer key is commonly denoted as the target (or label). The current model is run with the training dataset and produces a result, which is then compared with the target, for each input vector in the training dataset. Based on the result of the comparison and the specific learning algorithm being used, the parameters of the model are adjusted. The model fitting can include both variable selection and parameter estimation.
Successively, the fitted model is used to predict the responses for the observations in a second dataset called the validation dataset.[3] The validation dataset provides an unbiased evaluation of a model fit on the training dataset while tuning the model's hyperparameters[5] (e.g. the number of hidden units (layers and layer widths) in a neural network[4]). Validation datasets can be used for regularization by early stopping (stopping training when the error on the validation dataset increases, as this is a sign of overfitting to the training dataset).[6] This simple procedure is complicated in practice by the fact that the validation dataset's error may fluctuate during training, producing multiple local minima. This complication has led to the creation of many ad-hoc rules for deciding when overfitting has truly begun.[6]
Finally, the test dataset is a dataset used to provide an unbiased evaluation of a final model fit on the training dataset.[5] If the data in the test dataset has never been used in training (for example in cross-validation), the test dataset is also called a holdout dataset. The term "validation set" is sometimes used instead of "test set" in some literature (e.g., if the original dataset was partitioned into only two subsets, the test set might be referred to as the validation set).[5]
Training dataset
A training dataset is a dataset of examples used during the learning process and is used to fit the parameters (e.g., weights) of, for example, a classifier.[7][8]
For classification tasks, a supervised learning algorithm looks at the training dataset to determine, or learn, the optimal combinations of variables that will generate a good predictive model.[9] The goal is to produce a trained (fitted) model that generalizes well to new, unknown data.[10] The fitted model is evaluated using “new” examples from the held-out datasets (validation and test datasets) to estimate the model’s accuracy in classifying new data.[5] To reduce the risk of issues such as overfitting, the examples in the validation and test datasets should not be used to train the model.[5]
Most approaches that search through training data for empirical relationships tend to overfit the data, meaning that they can identify and exploit apparent relationships in the training data that do not hold in general.
Validation dataset
A validation dataset is a dataset of examples used to tune the hyperparameters (i.e. the architecture) of a classifier. It is sometimes also called the development set or the "dev set". An example of a hyperparameter for artificial neural networks includes the number of hidden units in each layer.[7][8] It, as well as the testing set (as mentioned above), should follow the same probability distribution as the training dataset.
In order to avoid overfitting, when any classification parameter needs to be adjusted, it is necessary to have a validation dataset in addition to the training and test datasets. For example, if the most suitable classifier for the problem is sought, the training dataset is used to train the different candidate classifiers, the validation dataset is used to compare their performances and decide which one to take and, finally, the test dataset is used to obtain the performance characteristics such as accuracy, sensitivity, specificity, F-measure, and so on. The validation dataset functions as a hybrid: it is training data used for testing, but neither as part of the low-level training nor as part of the final testing.
The basic process of using a validation dataset for model selection (as part of training dataset, validation dataset, and test dataset) is:[8][11]
Since our goal is to find the network having the best performance on new data, the simplest approach to the comparison of different networks is to evaluate the error function using data which is independent of that used for training. Various networks are trained by minimization of an appropriate error function defined with respect to a training data set. The performance of the networks is then compared by evaluating the error function using an independent validation set, and the network having the smallest error with respect to the validation set is selected. This approach is called the hold out method. Since this procedure can itself lead to some overfitting to the validation set, the performance of the selected network should be confirmed by measuring its performance on a third independent set of data called a test set.
An application of this process is in early stopping, where the candidate models are successive iterations of the same network, and training stops when the error on the validation set grows, choosing the previous model (the one with minimum error).
Test dataset
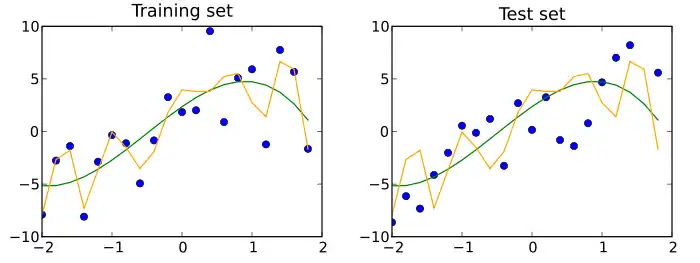
A test dataset is a dataset that is independent of the training dataset, but that follows the same probability distribution as the training dataset. If a model fit to the training dataset also fits the test dataset well, minimal overfitting has taken place (see figure below). A better fitting of the training dataset as opposed to the test dataset usually points to overfitting.
A test set is therefore a set of examples used only to assess the performance (i.e. generalization) of a fully specified classifier.[7][8] To do this, the final model is used to predict classifications of examples in the test set. Those predictions are compared to the examples' true classifications to assess the model's accuracy.[9]
In a scenario where both validation and test datasets are used, the test dataset is typically used to assess the final model that is selected during the validation process. In the case where the original dataset is partitioned into two subsets (training and test datasets), the test dataset might assess the model only once (e.g., in the holdout method).[12] Note that some sources advise against such a method.[10] However, when using a method such as cross-validation, two partitions can be sufficient and effective since results are averaged after repeated rounds of model training and testing to help reduce bias and variability.[5][10]
Confusion in terminology
The terms test set and validation set are sometimes used in a way that flips their meaning in both industry and academia. In the erroneous usage, "test set" becomes the development set, and "validation set" is the independent set used to evaluate the performance of a fully specified classifier.
The literature on machine learning often reverses the meaning of “validation” and “test” sets. This is the most blatant example of the terminological confusion that pervades artificial intelligence research.[13]
Cross-validation
A dataset can be repeatedly split into a training dataset and a validation dataset: this is known as cross-validation. These repeated partitions can be done in various ways, such as dividing into 2 equal datasets and using them as training/validation, and then validation/training, or repeatedly selecting a random subset as a validation dataset. To validate the model performance, sometimes an additional test dataset that was held out from cross-validation is used.
Hierarchical classification
Another example of parameter adjustment is hierarchical classification (sometimes referred to as instance space decomposition[14]), which splits a complete multi-class problem into a set of smaller classification problems. It serves for learning more accurate concepts due to simpler classification boundaries in subtasks and individual feature selection procedures for subtasks. When doing classification decomposition, the central choice is the order of combination of smaller classification steps, called the classification path. Depending on the application, it can be derived from the confusion matrix and, uncovering the reasons for typical errors and finding ways to prevent the system make those in the future. For example,[15] on the validation set one can see which classes are most frequently mutually confused by the system and then the instance space decomposition is done as follows: firstly, the classification is done among well recognizable classes, and the difficult to separate classes are treated as a single joint class, and finally, as a second classification step the joint class is classified into the two initially mutually confused classes.
See also
- Statistical classification
- List of datasets for machine learning research
References
- Ron Kohavi; Foster Provost (1998). "Glossary of terms". Machine Learning. 30: 271–274. doi:10.1023/A:1007411609915.
- Bishop, Christopher M. (2006). Pattern Recognition and Machine Learning. New York: Springer. p. vii. ISBN 0-387-31073-8.
Pattern recognition has its origins in engineering, whereas machine learning grew out of computer science. However, these activities can be viewed as two facets of the same field, and together they have undergone substantial development over the past ten years.
- James, Gareth (2013). An Introduction to Statistical Learning: with Applications in R. Springer. p. 176. ISBN 978-1461471370.
- Ripley, Brian (1996). Pattern Recognition and Neural Networks. Cambridge University Press. p. 354. ISBN 978-0521717700.
- Brownlee, Jason (2017-07-13). "What is the Difference Between Test and Validation Datasets?". Retrieved 2017-10-12.
- Prechelt, Lutz; Geneviève B. Orr (2012-01-01). "Early Stopping — But When?". In Grégoire Montavon; Klaus-Robert Müller (eds.). Neural Networks: Tricks of the Trade. Lecture Notes in Computer Science. Springer Berlin Heidelberg. pp. 53–67. doi:10.1007/978-3-642-35289-8_5. ISBN 978-3-642-35289-8.
- Ripley, B.D. (1996) Pattern Recognition and Neural Networks, Cambridge: Cambridge University Press, p. 354
- "Subject: What are the population, sample, training set, design set, validation set, and test set?", Neural Network FAQ, part 1 of 7: Introduction (txt), comp.ai.neural-nets, Sarle, W.S., ed. (1997, last modified 2002-05-17)
- Larose, D. T.; Larose, C. D. (2014). Discovering knowledge in data : an introduction to data mining. Hoboken: Wiley. doi:10.1002/9781118874059. ISBN 978-0-470-90874-7. OCLC 869460667.
- Xu, Yun; Goodacre, Royston (2018). "On Splitting Training and Validation Set: A Comparative Study of Cross-Validation, Bootstrap and Systematic Sampling for Estimating the Generalization Performance of Supervised Learning". Journal of Analysis and Testing. Springer Science and Business Media LLC. 2 (3): 249–262. doi:10.1007/s41664-018-0068-2. ISSN 2096-241X.
- Bishop, C.M. (1995), Neural Networks for Pattern Recognition, Oxford: Oxford University Press, p. 372
- Kohavi, Ron (2001-03-03). "A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection". 14. Cite journal requires
|journal=(help) - Ripley, Brian D. (2009). Pattern recognition and neural networks. Cambridge Univ. Press. pp. Glossary. ISBN 9780521717700. OCLC 601063414.
- Cohen, S.; Rokach, L.; Maimon, O. (2007). "Decision-tree instance-space decomposition with grouped gain-ratio". Information Sciences. Elsevier. 177 (17): 3592–3612. doi:10.1016/j.ins.2007.01.016.
- Sidorova, J., Badia, T. "ESEDA: tool for enhanced speech emotion detection and analysis". The 4th International Conference on Automated Solutions for Cross Media Content and Multi-Channel Distribution (AXMEDIS 2008). Florence, November, 17-19, pp. 257–260. IEEE press.
External links
- FAQ: What are the population, sample, training set, design set, validation set, and test set?
- What is the Difference Between Test and Validation Datasets?
- What is training, validation, and testing data-sets scenario in machine learning?
- Is there a rule-of-thumb for how to divide a dataset into training and validation sets?