Universal Dependencies
Universal Dependencies, frequently abbreviated as UD, is an international cooperative project to create treebanks of the world's languages. These treebanks are openly accessible and available. Core applications are automated text processing in the field of natural language processing (NLP) and research into natural language syntax and grammar, especially within linguistic typology. The project's primary aim is to achieve cross-linguistic consistency of annotation, while still permitting language-specific extensions when necessary. The annotation scheme has it roots in three related projects: Stanford Dependencies,[1] Google universal part-of-speech tags,[2] and the Interset interlingua[3] for morphosyntactic tagsets. The UD annotation scheme uses a representation in the form of dependency trees as opposed to a phrase structure trees. At the present time (February 2019), there are just over 100 treebanks of more than 70 languages available in the UD inventory.
Dependency structures
The UD annotation scheme produces syntactic analyses of sentences in terms of the dependencies of dependency grammar. Each dependency is characterized in terms of a syntactic function, which is shown using a label on the dependency edge. For example:[4]
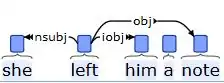
This analysis shows that she, him, and a note are dependents of the left. The pronoun she is identified as a nominal subject (nsubj), the pronoun him as an indirect object (iobj) and the noun phrase a note as a direct object (obj) -- there is a further dependency that connects a to note, although it is not shown. A second example:
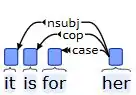
This analysis identifies it as the subject (nsubj), is as the copula (cop), and for as a case marker (case), all of which are shown as dependents of the root word her, which is a pronoun. The next example includes an expletive and an oblique object:
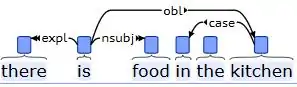
This analysis identifies there as an expletive (expl), food as a nominal subject (nsubj), kitchen as an oblique object (obl), and in as a case marker (case) -- there is also a dependency connecting the to kitchen, but it is not shown. Note that the copula is in this case is positioned as the root of the sentence, a fact that is contrary to how the copula is analyzed in the second example just above, where it is positioned as a dependent of the root.
The examples of UD annotation just provided can of course give only an impression of the nature of the UD project and its annotation scheme. The emphasis for UD is on producing cross-linguistically consistent dependency analyses in order to facilitate structural parallelism across diverse languages. To this end, UD uses a universal POS tagset for all languages—although a given language does not have to make use of each tag. More specific information can be added to each word by means of a free morpho-syntactic feature set. The universal labels of dependency links can be specified with secondary relations, which are indicated as a secondary label behind a colon, e.g. nsubj:pass, following the "universal:extension" format.
Function words
Within the dependency grammar community, the UD annotation scheme is controversial. The main bone of contention concerns the analysis of function words. UD chooses to subordinate function words to content words,[5] a practice that is contrary to most works in the tradition of dependency grammar.[6] To briefly illustrate this controversy, UD would produce the following structural analysis of the sentence given:
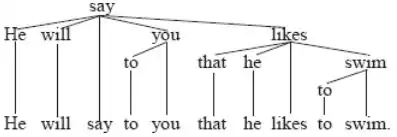
This example is taken from the article here.[7] An alternative convention for showing dependencies is now used, different from the convention above. Since the syntactic functions are not important for the point at hand, they are excluded from this structural analysis. What is important is the manner in which this UD analysis subordinates the auxiliary verb will to the content verb say, the preposition to to the pronoun you, the subordinator that to the content verb likes, and the particle to to the content verb swim.
A more traditional dependency grammar analysis of this sentence, one that is motivated more by syntactic considerations than by semantic ones, looks like this:[8]
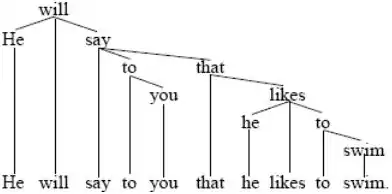
This traditional analysis subordinates the content verb say to the auxiliary verb will, the pronoun you to the preposition to, the content verb likes to the subordinator that, and the content verb swim to the participle to.
Notes
- "Stanford Dependencies". nlp.stanford.edu. The Stanford Natural Language Processing Group. Retrieved 8 May 2020.
- Petrov, Slav (11 Apr 2011). "A Universal Part-of-Speech Tagset". arXiv:1104.2086 [cs.CL].
- "Interset". cuni.cz. Institute of Formal and Applied Linguistics (Czech Republic). Retrieved 8 May 2020.
- The three example analyses that appear in this section have been taken from the UD webpage here, examples 3, 21, and 23.
- The choice was led by Nivre (2015).
- The controversy surrounding UD and the status of function words in dependency grammar in general are discussed at length in Osborne & Gerdes (2019).
- The structure is (1b) in Osborne & Gerdes (2019) article.
- This structure is (1c) in Osborne & Gerdes (2019) article.
References
- de Marneffe, Marie-Catherine, Bill MacCartney and Christopher D. Manning. 2006. Generating Typed Dependency Parses from Phrase Structure Parses. In the Proceedings of the Language Resources and Evaluation Conference (LREC) 2006, 449–454. Genoa.
- de Marneffe, Marie-Catherine and Christopher D. Manning. 2008. The Stanford typed dependency representation. Proceedings of the COLING Workshop on Cross-Framework and Cross-Domain Parser Evaluation, 92–97. Sofia. DOI: https://doi.org/10.3115/1608858.1608859
- de Marneffe, Marie-Catherine, Timothy Dozat, Natalia Silvaire, Katrin Haverinen, Filip Ginter, Joakim Nivre, Christopher D. Manning. 2014. Universal Stanford Dependencies: A cross-linguistic typology. In The International Conference on Language Resources and Evaluation (LREC) 2014, 4585–4592.
- Nivre, Joakim. 2015. Towards a Universal Grammar for Natural Language Processing. CICLING 2015: 16th International Conference on Intelligent Text Processing and Computational Linguistics, 3-16. DOI: https://doi.org/10.1007/978-3-319-18111-0_1
- Osborne, Timothy & Kim Gerdes. 2019. The status of function words in dependency grammar: A critique of Universal Dependencies (UD). Glossa: A Journal of General Linguistics 4(1), 17. DOI: http://doi.org/10.5334/gjgl.537.
- Petrov, Slav, Dipon Das, and Ryan McDonald. 2012. A universal part-of-speech tagset. The International Conference on Language Resources and Evaluation (LREC) 2012, 2089–2096. Istanbul.
- Zeman, Daniel. 2008. Reusable tagset conversion using tagset drivers. In The International Conference on Language Resources and Evaluation (LREC) 2008, 213–218. Marrakech.