Attention (machine learning)
In the context of neural networks, attention is a technique that mimics cognitive attention. The effect enhances the important parts of the input data and fades out the rest -- the thought being that the network should devote more computing power on that small but important part of the data. Which part of the data is more important than others depends on the context and is learned through training data by gradient descent.
They are used in a wide variety of machine learning models, including in natural language processing and computer vision.[1][2]
Transformer networks make extensive use of attention mechanisms to achieve their expressive power.[1] Computer vision systems based on convolutional neural networks can also benefit from attention mechanisms.
The two most common attention techniques used are dot-product attention, which uses the dot product between vectors to determine attention, and multi-head attention, which combines several different attention mechanisms to direct the overall attention of a network or sub-network.
A Language Translation Example
To build a machine that translates English-to-French (see diagram below), one starts with an Encoder-Decoder and graft an attention unit to it. The attention unit is a fully connected neural network that feeds a weighted combination of encoder outputs into the decoder.
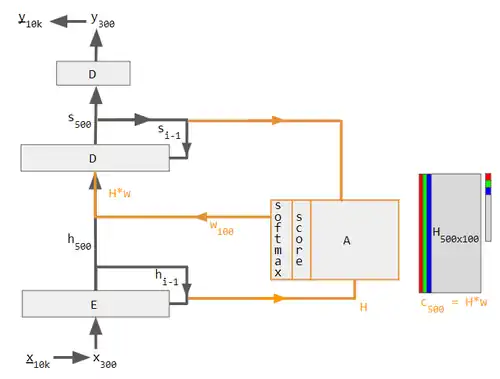 Encoder-Decoder with attention. This diagram uses specific values to relieve an already cluttered notation alphabet soup. The left part (in black) is the Encoder-Decoder, the middle part (in orange) is the attention unit, and the right part (in grey & colors) is the computed data. Grey regions in H matrix and w vector are zero values. Subscripts are examples of vector sizes, except for i-1 which indicate time step.
|
|
This table shows the calculations at each time step. For clarity, it uses specific numerical values and shapes rather than letters. The nested shapes depict the summarizing nature of h, where each h contains a history of the words that came before it. Here, the attention scores were cooked up to get the desired attention weights.
| step | x | h, H = encoder output these are 500x1 vectors represented as shapes | yi-1 = decoder input to Attention | alignment score | w = attention weight = softmax( score ) | c = context vector = H*w | y = decoder output |
| 1 | I | - | - | - | - | - | |
| 2 | love | - | - | - | - | - | |
| 3 | you | - | - | - | - | - | |
| 4 | - | - | y1 does not exist yet so we use this instead | [.63 -3.2 -2.5 .5 .5 ...] | [.94 .02 .04 0 0 ...] | .94 * | je |
| 5 | - | - | y1 | [-1.5 -3.9 .57 .5 .5 ...] | [.11 .01 .88 0 0 ...] | .11 * | t' |
| 6 | - | - | y2 | [-2.8 .64 -3.2 .5 .5 ...] | [.03 .95 .02 0 0 ...] | .03 * | aime |
Viewed as a matrix, the attention weights show how the network adjusts its focus according to context.
| I | love | you | |
| je | .94 | .02 | .04 |
| t' | .11 | .01 | .88 |
| aime | .03 | .95 | .02 |
This view of the attention weights addresses the "explainability" problem that neural networks are criticized for. Networks that perform verbatim translation without regard to word order would have a diagonally dominant matrix if they were analyzable in these terms. The off-diagonal dominance shows that the attention mechanism is more nuanced. On the first pass through the decoder, 94% of the attention weight is on the first English word "I", so the network offers the word "je". On the second pass of the decoder, 88% of the attention weight is on the third English word "you", so it offers"t'". On the last pass, 95% of the attention weight is on the second English word "love", so it offers "aime".
References
- Vaswani, Ashish; Shazeer, Noam; Parmar, Niki; Uszkoreit, Jakob; Jones, Llion; Gomez, Aidan N.; Kaiser, Lukasz; Polosukhin, Illia (2017-12-05). "Attention Is All You Need". arXiv:1706.03762 [cs.CL].
- Ramachandran, Prajit; Parmar, Niki; Vaswani, Ashish; Bello, Irwan; Levskaya, Anselm; Shlens, Jonathon (2019-06-13). "Stand-Alone Self-Attention in Vision Models". arXiv:1906.05909 [cs.CV].
External links
- Alex Graves (4 May 2020), Attention and Memory in Deep Learning (video lecture), DeepMind / UCL, via YouTube.
- Rasa Algorithm Whiteboard - Attention via YouTube
Differentiable computing | |||||||
|---|---|---|---|---|---|---|---|
| General |  | ||||||
| Concepts | |||||||
| Programming languages | |||||||
| Application | |||||||
| Hardware | |||||||
| Software library | |||||||
| Implementation |
| ||||||
| People | |||||||
| Organizations | |||||||
| |||||||