Weight-balanced tree
In computer science, weight-balanced binary trees (WBTs) are a type of self-balancing binary search trees that can be used to implement dynamic sets, dictionaries (maps) and sequences.[1] These trees were introduced by Nievergelt and Reingold in the 1970s as trees of bounded balance, or BB[α] trees.[2][3] Their more common name is due to Knuth.[4]
Like other self-balancing trees, WBTs store bookkeeping information pertaining to balance in their nodes and perform rotations to restore balance when it is disturbed by insertion or deletion operations. Specifically, each node stores the size of the subtree rooted at the node, and the sizes of left and right subtrees are kept within some factor of each other. Unlike the balance information in AVL trees (which store the height of subtrees) and red-black trees (which store a fictional "color" bit), the bookkeeping information in a WBT is an actually useful property for applications: the number of elements in a tree is equal to the size of its root, and the size information is exactly the information needed to implement the operations of an order statistic tree, viz., getting the n'th largest element in a set or determining an element's index in sorted order.[5]
Weight-balanced trees are popular in the functional programming community and are used to implement sets and maps in MIT Scheme, SLIB and implementations of Haskell.[6][4]
Description
A weight-balanced tree is a binary search tree that stores the sizes of subtrees in the nodes. That is, a node has fields
- key, of any ordered type
- value (optional, only for mappings)
- left, right, pointer to node
- size, of type integer.
By definition, the size of a leaf (typically represented by a nil pointer) is zero. The size of an internal node is the sum of sizes of its two children, plus one (size[n] = size[n.left] + size[n.right] + 1). Based on the size, one defines the weight as weight[n] = size[n] + 1.[lower-alpha 1]
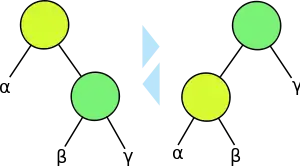
Operations that modify the tree must make sure that the weight of the left and right subtrees of every node remain within some factor α of each other, using the same rebalancing operations used in AVL trees: rotations and double rotations. Formally, node balance is defined as follows:
- A node is α-weight-balanced if weight[n.left] ≥ α·weight[n] and weight[n.right] ≥ α·weight[n].[7]
Here, α is a numerical parameter to be determined when implementing weight balanced trees. Larger values of α produce "more balanced" trees, but not all values of α are appropriate; Nievergelt and Reingold proved that

is a necessary condition for the balancing algorithm to work. Later work showed a lower bound of 2⁄11 for α, although it can be made arbitrarily small if a custom (and more complicated) rebalancing algorithm is used.[7]
Applying balancing correctly guarantees a tree of n elements will have height[7]

The number of balancing operations required in a sequence of n insertions and deletions is linear in n, i.e., balancing takes a constant amount of overhead in an amortized sense.[8]
While maintaining tree with the minimum search cost requires four kinds of double rotations (LL, LR, RL, RR as in AVL tree) in insert/delete operations, if we desire only logarithmic performance, LR and RL are the only rotations required in a single top-down pass.[9]
Set operations and bulk operations
Several set operations have been defined on weight-balanced trees: union, intersection and set difference. Then fast bulk operations on insertions or deletions can be implemented based on these set functions. These set operations rely on two helper operations, Split and Join. With the new operations, the implementation of weight-balanced trees can be more efficient and highly-parallelizable.[10][11]
- Join: The function Join is on two weight-balanced trees t1 and t2 and a key k and will return a tree containing all elements in t1, t2 as well as k. It requires k to be greater than all keys in t1 and smaller than all keys in t2. If the two trees have the balanced weight, Join simply create a new node with left subtree t1, root k and right subtree t2. Suppose that t1 has heavier weight than t2 (the other case is symmetric). Join follows the right spine of t1 until a node c which is balanced with t2. At this point a new node with left child c, root k and right child t2 is created to replace c. The new node may invalidate the weight-balanced invariant. This can be fixed with a single or a double rotation assuming
- Split: To split a weight-balanced tree into two smaller trees, those smaller than key x, and those larger than key x, first draw a path from the root by inserting x into the tree. After this insertion, all values less than x will be found on the left of the path, and all values greater than x will be found on the right. By applying Join, all the subtrees on the left side are merged bottom-up using keys on the path as intermediate nodes from bottom to top to form the left tree, and the right part is symmetric. For some applications, Split also returns a boolean value denoting if x appears in the tree. The cost of Split is , order of the height of the tree. This algorithm actually has nothing to do with any special properties of a weight-balanced tree, and thus is generic to other balancing schemes such as AVL trees.


The join algorithm is as follows:
function joinRightWB(TL, k, TR)
(l, k', c) = expose(TL)
if balance(|TL|, |TL|) return Node(TL, k, TR
else
T' = joinRightWB(c, k, TR)
(l1,k1, r1) = expose(T')
if (balance(l,T')) return Node(l, k'T')
else if (balance(|l|,|l1|) and balance(|l|+|l1|,|r1|))
return rotateLeft(Node(l, k', T'))
else return rotateLeft(Node(l, k', rotateRight(T'))
function joinLeftWB(TL, k, TR)
/* symmetric to joinRightWB */
function join(TL, k, TR)
if (heavy(TL, TR)) return joinRightWB(TL, k, TR)
if (heavy(TR, TL)) return joinLeftWB(TL, k, TR)
Node(TL, k, TR)
Here balance means two weights and are balanced. expose(v)=(l, k, r) means to extract a tree node 's left child , the key of the node and the right child . Node(l, k, r) means to create a node of left child , key and right child .







The split algorithm is as follows:
function split(T, k)
if (T = nil) return (nil, false, nil)
(L, (m, c), R) = expose(T)
if (k = m) return (L, true, R)
if (k < m)
(L', b, R') = split(L, k)
return (L', b, join(R', m, R))
if (k > m)
(L', b, R') = split(R, k)
return (join(L, m, L'), b, R))
The union of two weight-balanced trees t1 and t2 representing sets A and B, is a weight-balanced tree t that represents A ∪ B. The following recursive function computes this union:
function union(t1, t2):
if t1 = nil:
return t2
if t2 = nil:
return t1
t<, t> ← split t2 on t1.root
return join(union(left(t1), t<), t1.root, union(right(t1), t>))
Here, Split is presumed to return two trees: one holding the keys less its input key, one holding the greater keys. (The algorithm is non-destructive, but an in-place destructive version exists as well.)
The algorithm for intersection or difference is similar, but requires the Join2 helper routine that is the same as Join but without the middle key. Based on the new functions for union, intersection or difference, either one key or multiple keys can be inserted to or deleted from the weight-balanced tree. Since Split and Union call Join but do not deal with the balancing criteria of weight-balanced trees directly, such an implementation is usually called the join-based algorithms.
The complexity of each of union, intersection and difference is for two weight-balanced trees of sizes and . This complexity is optimal in terms of the number of comparisons. More importantly, since the recursive calls to union, intersection or difference are independent of each other, they can be executed in parallel with a parallel depth .[10] When , the join-based implementation has the same computational directed acyclic graph (DAG) as single-element insertion and deletion if the root of the larger tree is used to split the smaller tree.





Notes
References
- Tsakalidis, A. K. (1984). "Maintaining order in a generalized linked list". Acta Informatica. 21: 101–112. doi:10.1007/BF00289142.
- Nievergelt, J.; Reingold, E. M. (1973). "Binary Search Trees of Bounded Balance". SIAM Journal on Computing. 2: 33–43. doi:10.1137/0202005.
-
 This article incorporates public domain material from the NIST document: Black, Paul E. "BB(α) tree". Dictionary of Algorithms and Data Structures.
This article incorporates public domain material from the NIST document: Black, Paul E. "BB(α) tree". Dictionary of Algorithms and Data Structures. - Hirai, Y.; Yamamoto, K. (2011). "Balancing weight-balanced trees" (PDF). Journal of Functional Programming. 21 (3): 287. doi:10.1017/S0956796811000104.
- Roura, Salvador (2001). A new method for balancing binary search trees. ICALP. Lecture Notes in Computer Science. 2076. pp. 469–480. doi:10.1007/3-540-48224-5_39. ISBN 978-3-540-42287-7.
- Adams, Stephen (1993). "Functional Pearls: Efficient sets—a balancing act". Journal of Functional Programming. 3 (4): 553–561. doi:10.1017/S0956796800000885.
- Brass, Peter (2008). Advanced Data Structures. Cambridge University Press. pp. 61–71.
- Blum, Norbert; Mehlhorn, Kurt (1980). "On the average number of rebalancing operations in weight-balanced trees" (PDF). Theoretical Computer Science. 11 (3): 303–320. doi:10.1016/0304-3975(80)90018-3.
- Cho, Seonghun; Sahni, Sartaj (2000). "A New Weight Balanced Binary Search Tree". International Journal of Foundations of Computer Science. 11 (3): 485–513. doi:10.1142/S0129054100000296.
- Blelloch, Guy E.; Ferizovic, Daniel; Sun, Yihan (2016), "Just Join for Parallel Ordered Sets", Symposium on Parallel Algorithms and Architectures, Proc. of 28th ACM Symp. Parallel Algorithms and Architectures (SPAA 2016), ACM, pp. 253–264, arXiv:1602.02120, doi:10.1145/2935764.2935768, ISBN 978-1-4503-4210-0.
- Adams, Stephen (1992), Implementing sets efficiently in a functional language, CiteSeerX 10.1.1.501.8427.