British National Corpus
The British National Corpus (BNC) is a 100-million-word text corpus of samples of written and spoken English from a wide range of sources.[1] The corpus covers British English of the late 20th century from a wide variety of genres, with the intention that it be a representative sample of spoken and written British English of that time.
History
The project to create the BNC involved the collaboration of three publishers (with the Oxford University Press as the lead collaborator, Longman and W. & R. Chambers), two universities (the University of Oxford and Lancaster University), and the British Library.[2] The creation of the BNC started in 1991 under the management of the BNC consortium, and the project was finished by 1994. There have been no additions of new samples after 1994, but the BNC underwent slight revisions before the release of the second edition BNC World (2001) and the third edition BNC XML Edition (2007).[3]
The BNC was the vision of computational linguists whose goal was a corpus of modern (at the time of building the corpus), naturally occurring language in the form of speech and text or writing that could be analyzed by a computer. Hence, it was compiled as a general corpus to pave the way for automatic search and processing in the field of corpus linguistics. One of the ways the BNC was to be differentiated from existing corpora at that time was to open up the data not just to academic research, but also to commercial and educational uses.[4]
The corpus was restricted to just British English, and was not extended to cover World Englishes. This was partly because a significant portion of the cost of the project was being funded by the British government which was logically interested in supporting documentation of its own linguistic variety.[4] Because of its potentially unprecedented size, the BNC required funds from the commercial and academic institutions as well. In turn, BNC data then became available for commercial and academic research.[4]
Description
The BNC is a monolingual corpus, as it records samples of language use in British English only, although occasionally words and phrases from other languages may also be present. It is a synchronic corpus, as only language use from the late 20th century is represented; the BNC is not meant to be a historical record of the development of British English over the ages.[3] From the beginning, those involved in the gathering of written data sought to make the BNC a balanced corpus, and hence looked for data in various mediums.[4]
Components and content
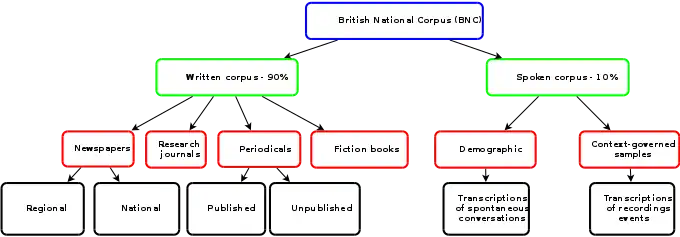
90% of the BNC is samples of written corpus use. These samples were extracted from regional and national newspapers, published research journals or periodicals from various academic fields, fiction and non-fiction books, other published material, and unpublished material such as leaflets, brochures, letters, essays written by students of differing academic levels, speeches, scripts, and many other types of texts.[5]
The remaining 10% of the BNC is samples of spoken language use. These are presented and recorded in the form of orthographic transcriptions. The spoken corpus consists of two parts: one part is demographic, containing the transcriptions of spontaneous natural conversations produced by volunteers of various age groups, social classes and originating from different regions. These conversations were produced in different situations, including formal business or government meetings to conversations on radio shows and phone-ins.[5] These were to account for both the demographic distribution of spoken language and those of linguistically significant variation due to context.[6]
The other part involves context-governed samples such as transcriptions of recordings made at specific types of meeting and event. All the original recordings transcribed for inclusion in the BNC have been deposited at the British Library Sound Archive. The majority of the recordings are freely available from the Oxford University Phonetics Laboratory.
Sub-corpora and tagging
Two sub-corpora (subsets of the BNC data) have been released: BNC Baby and BNC Sampler. Both these sub-corpora may be ordered online via the BNC webpage.[7] BNC Baby is a sub-corpus of BNC that consists of four sets of samples, each containing one million words tagged as they are in BNC itself. The words in each sample set correspond to a specific genre label. One sample set contains spoken conversation and the other three sample sets contain written text: academic writing, fiction and newspapers respectively.[8] The latest (third) edition has been released and comes in XML format.[9] The BNC Sampler is a two-part sub-corpora, a part each for written and spoken data; each part contains one million words. The BNC Sampler was originally used in a project to work out how to improve the tagging process for the BNC, which eventually led to the BNC World edition. Throughout the project, the BNC Sampler was improved with increasing expertise and knowledge for tagging to arrive at its current form.[10]
The BNC corpus has been tagged for grammatical information (part of speech). The tagging system, named CLAWS, went through improvements to yield the latest CLAWS4 system, which is used for tagging the BNC. CLAWS1 was based on a hidden Markov model and, when employed in automatic tagging, managed to successfully tag 96% to 97% of each text analyzed. CLAWS1 was upgraded to CLAWS2 by removing the need for manual processing to prepare the texts for automatic tagging. The latest version, CLAWS4, includes improvements such as more powerful word-sense disambiguation (WSD) abilities, and the ability to deal with variation in orthography and markup language. Later work on the tagging system looked at increasing the success rates in automatic tagging and reducing the work needed for manual processing, while maintaining effectiveness and efficiency by introducing software to replace some of the manual work.[2][11] Subsequently, a new program called the "Template Tagger" was introduced for a corrective function. Tags indicating ambiguity were later added. Manual tagging is still necessary, as CLAWS4 is still unable to deal with foreign words.[12][13]
TEI and access
The corpus is marked up following the recommendations of the Text Encoding Initiative (TEI) and includes full linguistic annotation and contextual information.[14] The licence for the CLAWS4 part-of-speech tagger may be purchased to use the tagger.[15] Alternatively, a tagging service is offered at Lancaster University.[16] The BNC itself may be ordered with either a personal or institutional license. The edition available is the BNC XML edition and it comes with the Xaira search engine software. Ordering may be carried out via the BNC website.[17] An online corpus manager, BNCweb, has been developed for the BNC XML edition. The interface is designed to be easy to use, and the program offers query features and functions for corpus analysis. Users can retrieve results and data from searches and analyses.[18]
Permission issues
The BNC was the first text corpus of its size to be made widely available. This could be attributed to the standard forms of agreement, between rights owners and the Consortium on the one hand, and between corpus users and the Consortium on the other. Intellectual property rights owners were sought for their agreement with the standard licence, including willingness to incorporate their materials in the corpus without any fees. This arrangement may have been facilitated by the originality of the concept and the prominence associated with the project. However, it was a challenge to keep the identity of contributors hidden without discrediting the value of their work. Any distinct allusion to the identity of contributors was largely removed; the alternative solution of substituting the identity of a contributor with a different name was discussed, but not considered feasible.[6]
Additionally, contributors had earlier been asked only to incorporate transcribed versions of their speech and not the speech itself. While permission could be sought from initial contributors again, the lack of success in the anonymization process meant that it would be challenging to seek materials from initial contributors. At the same time, two factors compounded the unwillingness of rights owners to donate their materials: full texts were to be excluded, and there was no motivation for them to disseminate information using the corpus, particularly since the corpus operates on a non-commercial basis.[6]
Problems and limitations
Categories
By 2001, the BNC still had no text categorisation for written texts beyond that of domain, and no categorisation for spoken texts except by context and demographic or socio-economic classes. For example, a wide variety of imaginative texts (novels, short stories, poems, and drama scripts) were included in the BNC, but such inclusions were deemed useless as researchers were unable to easily retrieve the subgenres on which they wanted to work (e.g., poetry). Because this metadata was omitted in the file headers and in all BNC documentation, there was no way to know whether an "imaginative" text actually came from a novel, a short story, a drama script or a collection of poems unless the title actually included words such as "novel" or "poem").[19]
With the 2002 introduction of a new version, the BNC World Edition, BNC attempted to deal with this problem. Besides domain, there are now 70 categories for genre for both spoken and written data, and so researchers can now specifically retrieve texts by genre. Even after these additions, however, implementation is still tricky, as assigning a genre or subgenre to a text is not straightforward. The divisions are less clear for spoken data than they are for written data, as there was more variation in topic and execution. Also, there will always be possible subsets of genres of each subgenre. How far genres are subdivided is pre-determined for the sake of a default, but researchers have the option of making the divisions more general or specific according to their needs. Categorisation is also a problem, as certain texts, while deemed to belong to an interdisciplinary genre such as linguistics, include content that is subsequently categorised into either arts or science categories due to the nature of their content.[20]
Classification and discourse
Some texts were classified under the wrong category, usually because of a misleading title. Users cannot always rely on the titles of the files as indications of their real content: For example, many texts with "lecture" in their title are actually classroom discussions or tutorial seminars involving a very small group of people, or were popular lectures (addressed to a general audience rather than to students at an institution of higher learning).[19] One reason is that genre and subgenre labels can only be assigned for the majority of the texts in a category. There are subgenres within genres, and for each text the content may not be uniform throughout and may span multiple subgenres.[20] Also, production pressures coupled with insufficient information led to hasty decisions, resulting in inaccuracy and inconsistency in records.[6]
The proportion of written to spoken material in the BNC is 10:1, making spoken material under-represented. This is because the cost of collecting and transcribing one million words of naturally occurring speech is at least 10 times higher than the cost of adding another million words of newspaper text. Some linguists have argued that this represents a deficiency in the corpus, since speech and writing are both equally important in a language.[6] The BNC is not ideal for the study of many features of spoken discourse, since most of its transcripts are orthographic. Paralinguistic features are only roughly indicated.[21]
Limitations and misappropriates
Despite being an excellent source of lexical information, the BNC can only really be used to study a limited set of grammatical patterns, particularly those which have distinctive lexical correlates. While it is easy enough to find all the occurrences of "enjoy", and to sort them according to the part-of-speech category of the following word, it requires additional work to find all cases of verbs followed by a gerund, since the SARA index of the BNC does not include part-of-speech categories such as "all verbs" or "all V-ing forms".[21]
Some lexical correlates are also too ambiguous to allow them to be used in queries: any search for restrictive relative clauses would provide the user with irrelevant data, given the number of other uses of wh-pronouns and of that in the language (not to mention the impossibility of identifying relative clauses with pronoun deletion, as in "the man I saw"). Particular semantic and pragmatic categories (doubt, cognisance, disagreements, summaries, etc.) are difficult to locate for the same reason. This means, for example, that while one can compare speech by men and by women, one cannot compare speech to women and to men.[21]
The nature of the BNC as a large mixed corpus renders it unsuitable for the study of highly specific text-types or genres, as any one of them is likely to be inadequately represented and may not be recognisable from the encoding. For example, there are very few business letters and service encounters in the BNC, and those wishing to explore their specific conventions would do better to compile a small corpus including only texts of those types.[21]
Uses
English language education
There are two general ways in which corpus material can be used in language teaching.[21]
Firstly, publishers and researchers could use corpus samples to create language-learning references, syllabuses and other related tools or materials. For example, the BNC was used by a group of Japanese researchers as a tool in their creation of an English-language–learning website for learners of English for specific purposes (ESP).[22] The website enabled English-language learners to download frequently heard and used sentence patterns, and then base their own usage of the English language on these sentence patterns. The BNC served as the source from which the frequently used expressions were extracted. In using this website, users thus relied on reference samples from the BNC to guide them in their learning of the English language. Such creation of materials that facilitate language-learning typically involves the use of very large corpora (comparable to the size of the BNC), as well as advanced software and technology. A large amount of money, time, and expertise in the field of computational linguistics are invested in the development of such language-learning material.[21]
Secondly, the analysis of the corpus can be incorporated directly into the language teaching and learning environment. With this method, language learners are given the opportunity to categorize language data from the corpus and subsequently form conclusions about the patterns and features of their target language from their categorizations. This method involves a greater amount of work on the part of the language leaner and is referred to as “data-driven learning” by Tim Johns. The corpus data used for data-driven learning is relatively smaller, and consequently the generalisations made about the target language may be of limited value.[21] In general, the BNC is useful as a reference source for the purposes of producing and perceiving text. The BNC can be used as a reference source when studying the use of individual words in various contexts, so that learners become familiar with the different ways to use particular words in suitable contexts.[21] Other than language-related information, encyclopedic information is also found in the BNC. Learners perusing data from the BNC are also introduced to British cultural features and stereotypes.[21]
Bilingual dictionaries, tests and evaluation
The BNC was the source of more than 12,000 words and phrases used for the production of a range of bilingual dictionaries in India in 2012, translating 22 local languages into English. This was part of a larger movement to push for improvements in education, the preservation of India's vernacular languages, and the development of translation work.[23] The large size of the BNC provides a large-scale resource on which to test programs.[24] It has been used as a test bed for the Text Encoding Initiative (TEI) guidelines. The BNC has also been used to provide 20 million words to evaluate English subcategorization acquisition systems for the Senseval initiative for computational analysis of meaning.[25]
Collocational Evidence from the British National Corpus
Hoffman & Lehmann (2000) explored the mechanisms behind speakers' ability to manipulate their large inventory of collocations which are ready for use and can be easily expanded grammatically or syntactically to adapt to the current speech situation. Word combinations occurring in low frequency were extracted from the BNC to offer some insight into it.[26]
Collocational behaviour of man and woman
Pearce (2008) examined the representation of men and women in this corpus by using Sketch Engine. The corpus query tool was used to explore grammatical behaviour of the noun lemmas "man" and "woman" (i.e., the nouns "man"/"men" and "woman"/"women").[27]
Non-sentential Utterances: A Corpus Study
Fernandez & Ginzburg (2002) investigated dialogue which included non-sentiential utterances using the BNC.[28]
A corpus-based EAP course for NNS doctoral students
Lee & Swales (2006) designed an experimental course in corpus-informed English for Academic Purposes (EAP) for doctoral students at the English Language Institute (ELI) of the University of Michigan in the US.[29]
Participants used three main corpora as the basis of their investigations: Hyland's Research Article Corpus, the Michigan Corpus of Academic Spoken English (MICASE), and academic texts from the BNC.[29]
Future work
Morphological processing
As part of ongoing work on morphological processing, a key area of Natural Language Processing (NLP), data from the BNC was used to test the accuracy, reliability and swiftness of computational tools developed to facilitate the analysis and processing of morphological markers in British English.[30] The computational tools involved a program that enabled the analysis of inflectional morphology in British English (known as an analyser) and a program that generated morphological markings based on the analysis from the analyser. Data from the BNC was also used to build up an extensive repository of information about British English morphological markers. In particular, approximately 1,100 lemmas were extracted from the BNC and compiled into a checklist which was consulted by the morphological generator before verbs that allowed consonant doubling were accurately inflected.[30] Since the BNC represents a recognizable effort to collect and subsequently process such a large amount of data, it has become an influential forerunner in the field and a model or exemplary corpus on which the development of later corpora was based.[31]
BNC2014
In July 2014, Cambridge University Press and the Centre for Corpus Approaches to Social Science (CASS) announced at Lancaster University that a new British National Corpus - the BNC2014[32] - was under compilation.[33] The first stage of the collaborative project between the two institutions was to compile a new spoken corpus of British English from the early to mid 2010s.[34] The 11.5-million-word Spoken British National Corpus 2014 was released to the public on 25 September 2017.[35] The 100-million-word written component of the BNC2014 is currently being compiled, and is scheduled to be released to the public in the Autumn of 2018.[36]
See also
References
- Burnard, Lou; Aston, Guy (1998). The BNC handbook: exploring the British National Corpus. Edinburgh: Edinburgh University Press. p. xiii. ISBN 0-7486-1055-3.
- Leech, Geoffrey; Garside, Roger; Bryant, Michael (1994). "Corpus-based research into language: in honour of Jan Aarts". In N. Oostdjik & P. Haan (ed.). The large-scale grammatical tagging of text: Experience with the British National Corpus. Netherlands: Rodopi Publishers. pp. 47–63.
- What is the BNC?. Retrieved 12 March 2012.
- Leech, Geoffrey (1993). "100 million words of English". English Today. 9 (1): 9–15. doi:10.1017/S0266078400006854.
- British National Corpus. Retrieved 12 March 2012.
- Burnard, Lou (2002). "Where did we go wrong? A retrospective look at the British National Corpus" (PDF). Retrieved 14 March 2012.
- "BNC Products". Retrieved 18 March 2012.
- Burnard, Lou (2003). "Reference Guide for BNC-baby". Retrieved 18 March 2012.
- "New edition of BNC Baby available". Retrieved 19 March 2012.
- "BNC Sampler: XML edition" (PDF). 2008. Retrieved 18 March 2012.
- Leech, Geoffrey; Garside, Roger; Bryant, Michael (1994). "Claws4: The Tagging Of The British National Corpus". Paper given at COLING'94, Lancaster: UK. CiteSeerX 10.1.1.13.3622. Cite journal requires
|journal=(help) - Leech, Geoffrey; Smith, Nicholas (2000). "The British National Corpus (Version 2) with Improved Word-class Tagging". UCREL, Lancaster University, UK. Retrieved 17 March 2012.
- Leech, Geoffrey; Smith, Nicholas (2000). "Automatic POS-Tagging of the Corpus". UCREL, Lancaster University, UK. Retrieved 17 March 2012.
- Burnard, Lou (1995). "Users Reference Guide for the British National Corpus" (PDF). Retrieved 18 March 2012.
- "Obtaining a license for the CLAWS tagger". UCREL, Lancaster University, UK. Retrieved 17 March 2012.
- "The CLAWS tagging service". UCREL, Lancaster University, UK. Retrieved 17 March 2012.
- "How to order". Retrieved 17 March 2012.
- Hoffmann, Sebastian; Evert, Stefan (2008). Corpus linguistics with BNCweb: a practical guide. Peter Lang. ISBN 978-3-631-56315-1.
- Lee, David (2001). "GENRES, REGISTERS, TEXT TYPES, DOMAINS, AND STYLES" (PDF). 5 (3): 37–72. Retrieved 15 March 2012. Cite journal requires
|journal=(help) - Lee, David (2002). "NOTES TO ACCOMPANY THE BNC WORLD EDITION (BIBLIOGRAPHICAL) INDEX" (PDF). Archived from the original (PDF) on 2013-09-23. Retrieved 17 March 2012.
- Aston, Guy (1998). "Learning English with the British National Corpus". Paper given at 6th Jornada de Corpus, Barcelona: UPF. Retrieved 16 March 2012.
- Minn, Danny; Sano, Hiroshi; Ino, Marie; Nakamura, Takahiro (2005). "Using the BNC to create and develop educational materials and a website for learners of English" (PDF). ICAME Journal. 29: 99–113. Retrieved 12 March 2012.
- "Bilingual dictionaries to promote India's mother tongues". Times of Oman. 14 March 2012. Archived from the original on 2010-12-31. Retrieved 17 March 2012.
- "What can I do with the BNC?". Retrieved 18 March 2012.
- Korhonen, Anna (2002). "EVALUATION RESOURCES for English Subcategorization Acquisition Systems". Archived from the original on 2012-12-13. Retrieved 18 March 2012.
- Hoffman, Sebastian; Lehmann, Hans Martin (2000). "Collocational Evidence from the British National Corpus". In Kirk, John M. (ed.). Corpora Galore: Analyses and Techniques in Describing English. Amsterdam: Rodopi. ISBN 9789042004191.
- Pearce, Michael (Nov 2008). "Investigating the collocational behaviour of MAN and WOMAN in the BNC using Sketch Engine" (PDF). Corpora. 3 (1): 1–29. doi:10.3366/E174950320800004X. Archived from the original (PDF) on 2015-06-27.
- Fernandez, Raquel; Jonathan Ginzburg (29 June 2002). "Non-sentential utterances: A corpus study" (PDF). Archived from the original (PDF) on 27 June 2015. Cite journal requires
|journal=(help) - Lee, David; John Swales (2006). "A corpus-based EAP course for NNS doctoral students: Moving from available specialized corpora to self-compiled corpora". English for Specific Purposes. 25 (1): 56–75. doi:10.1016/j.esp.2005.02.010.
- Minnen, Guido; Carroll, John; Pearce, Darren (2001). "Applied Morphological Processing of English" (PDF). Natural Language Engineering. 7 (3): 207–223. doi:10.1017/s1351324901002728.
- Čermák, František (2003). "Today's Corpus Linguistics: Some Open Questions". International Journal of Corpus Linguistics. 7 (2): 265–282. doi:10.1075/ijcl.7.2.06cer.
- "British National Corpus 2014".
- ESRC Centre for Corpus Approaches to Social Science (CASS) (28 July 2014). "Spoken BNC2014 project announcement". Retrieved 2016-10-07.
- "Centre for Corpus Approaches to Social Science". Retrieved 17 March 2015.
- "John Benjamins Publishing".
- "British National Corpus 2014".