Write Anywhere File Layout
The Write Anywhere File Layout (WAFL) is a proprietary file system that supports large, high-performance RAID arrays, quick restarts without lengthy consistency checks in the event of a crash or power failure, and growing the filesystems size quickly. It was designed by NetApp for use in its storage appliances like NetApp FAS, AFF, Cloud Volumes ONTAP and ONTAP Select.
| Developer(s) | NetApp |
|---|---|
| Full name | Write Anywhere File Layout |
| Limits | |
| Max. volume size | up to 100 TB (limited by containing aggregate size; variable maximum depending on platform; limited to 16TB when using Deduplication{ONTAP 8.2 now supports dedup to max volume size supported on platform}) |
| Max. file size | up to 16 TB[1] |
| Features | |
| Dates recorded | atime, ctime, mtime |
| File system permissions | UNIX permissions and ACLs |
| Transparent compression | Yes (Ontap 8.0 onwards) |
| Transparent encryption | Yes (since Ontap 9.1;[2] possible with 3rd party appliances like Decru DataFort for older versions) |
| Data deduplication | Yes (FAS Dedup: periodic online scans, block based;) |
| Copy-on-write | Yes |
| Other | |
| Supported operating systems | ONTAP |
Its author claims that WAFL is not a file system, although it includes one.[3] It tracks changes similarly to journaling file systems as logs (known as NVLOGs) in dedicated memory storage device non-volatile random access memory, referred to as NVRAM or NVMEM. WAFL provides mechanisms that enable a variety of file systems and technologies that want to access disk blocks.
Design
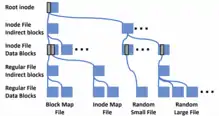
WAFL stores metadata, as well as data, in files; metadata, such as inodes and block maps indicating which blocks in the volume are allocated, are not stored in fixed locations in the file system. The top-level file in a volume is the inode file, which contains the inodes for all other files; the inode for the inode file itself, called the root inode, is stored in a block with a fixed location. An inode for a sufficiently small file contains the file's contents; otherwise, it contains a list of pointers to file data blocks or a list of pointers to indirect blocks containing lists of pointers to file data blocks, and so forth, with as many layers of indirect blocks as are necessary, forming a tree of blocks. All data and metadata blocks in the file system, other than the block containing the root inode, are stored in files in the file system. The root inode can thus be used to locate all of the blocks of all files other than the inode file.[4]
Main memory is used as a page cache for blocks from files. When a change is made to a block of a file, the copy in the page cache is updated and marked dirty, and the difference is logged in non-volatile memory in a log called the NVLOG. If the dirty block in the page cache is to be written to permanent storage, it is not rewritten to the block from which it was read; instead, a new block is allocated on permanent storage, the contents of the block are written to the new location, and the inode or indirect block that pointed to the block in question is updated in main memory. If the block containing the inode, or the indirect block, is to be written to permanent storage, it is also written to a new location, rather than being overwritten at its previous position. This is what the "Write Anywhere" in "Write Anywhere File Layout" refers to.[4]
As all blocks, other than the block containing the root inode, are found via the root inode, none of the changes written to permanent storage are visible on permanent storage until the root inode is updated. The root inode is updated by a process called a consistency point, in which all dirty blocks not yet written to permanent storage are written to permanent storage, and a new root inode is written out, pointing to the blocks in the new version of the inode file. At that point, all of the changes to the file system are visible on permanent storage, using the new root inode. The NVLOG entries for changes that are now visible are discarded to make room for log entries for subsequent changes. Consistency points are performed periodically or if the non-volatile memory is close to being full of log entries.[4]
If the server crashes before all changes to a file system have been made visible in a consistency point, the changes that have not been made visible are still in the NVLOG; when the server reboots, it replays all entries in the NVLOG, again making the changes recorded in the NVLOG, so that they will not be lost.
Features
As discussed above, WAFL does not store data or metadata in pre-determined locations on disk. Instead it automatically places data using temporal locality to write metadata alongside user data in a way designed to minimize the number of disk operations required to commit data to stable disk storage using single and dual parity based RAID.
Using a data placement based on temporal locality of reference can improve the performance of reading datasets which are read in a similar way to the way they were written (e.g. a database record and its associated index entry), however it can also cause fragmentation from the perspective of spatial locality of reference. On spinning HDDs this does not adversely affect files that are sequentially written, randomly read, or are subsequently read using the same temporal pattern, but does affect sequential read after random write spatial data access patterns because of magnetic head could be only in one position at a time to read data from platter while fragmentation does no effect on SSD drives.
Releases of ONTAP since 7.3.1 have included a number of techniques to optimize spatial data layout such as the reallocate command to perform scheduled and manual defragmentation, and the Write after Reading volume option which detects and automatically corrects suboptimal data access patterns caused by spatial fragmentation. Releases of ONTAP 8.1.1 include other techniques to automatically optimize contiguous free-space within the filesystem which also helps to maintain optimal data layouts for most data access patterns. Before 7G, the wafl scan reallocate command would need to be invoked from an advanced privilege level and could not be scheduled. Releases of ONTAP since 9.1 have included a number of techniques to optimize SSD usage such as Inline Data Compaction (in 9.1), starting with ONTAP 9.2 FabricPool functionality for automatic tiering of cold data to slow S3 storage and back if needed for SSD aggregates, and Cross Volume Deduplication within an aggregate with maximum of 800TiB for each aggregate.[5]
Snapshots

.png.webp)
WAFL supports snapshots, which are read-only copies of a file system. Snapshots are created by performing the same operations that are performed in a consistency point, but, instead of updating the root inode corresponding to the current state of the file system, saving a copy of the root inode. As all data and metadata in a file system can be found from the root inode, all data and metadata in a file system, as of the time when the snapshot is created, can be found from the snapshot's copy of the root inode. No other data needs to be copied to create a snapshot.[4]
Blocks are allocated when written using a block map, which keeps track of which blocks are in use and which blocks are free. An entry in the block map contains a bit indicating whether the block is in use in the current version of the file system and several bits, one per snapshot, indicating whether the block is in use in the snapshot. This ensures that data in a snapshot is not overwritten until the snapshot is deleted. Using block map all new writes and rewrites are written to new empty blocks, WAFL only reports that block rewrite successful, but no rewrites actually occur, this approach called Redirect-on-write (ROW) technique.[4] ROW is much faster on rewrite operations compare to Copy-on-write where old data block going to be rewritten in-place and captured in a snapshot needs to be copied first to space allocated for snapshot reserve in order to preserve original data, this generates additional data copy operations once system get rewrites to that block.
Snapshots provide online backups that can be accessed quickly, through special hidden directories in the file system, allowing users to recover files that have been accidentally deleted or modified.[4]
NetApp's Data ONTAP Release 7G operating system supports a read-write snapshot called FlexClone. Snapshots are basis for technologies like SnapMirror, SnapVault and Online Volume Move while features like FlexClone, SnapLock, SnapRestore are snapshot-like technologies leverage on WAFL capabilities and properties like manipulations with inodes. Starting with ONTAP 9.4 maximum number of snapshots supported for each FlexVol is 1024, while for previous versions max limit was 255.
Starting with ONTAP 9.5 snapshot sharing functionality were added to run deduplication scan across Active file system and snapshots, and deduplication savings is a magnitude of number of snapshots. Before 9.5 not deduplicated data locked in a snapshot couldn’t be used by deduplication process and runs only in active file system.
File and directory model
An important feature of WAFL is its support for both a Unix-style file and directory model for NFS clients and a Microsoft Windows-style file and directory model for SMB clients. WAFL also supports both security models, including a mode where different files on the same volume can have different security attributes attached to them. Unix can use either[6] access control lists (ACL) or a simple bitmask, whereas the more recent Windows model is based on access control lists. These two features make it possible to write a file to an SMB type of networked filesystem and access it later via NFS from a Unix workstation. Alongside ordinary files, WAFL can contain file-containers called LUNs with required special attributes like LUN serial number for block devices, which could be accessed using SAN protocols running on ONTAP OS software.
FlexVol
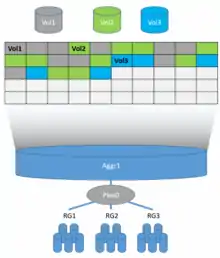
Each Flexible Volume (FlexVol) is a separate WAFL file system, located on an aggregate and distributed across all disks in the aggregate. Each aggregate can contain and usually has multiple FlexVol volumes. ONTAP during data optimization process including the "Tetris" which finishes with Consistency Points (see NVRAM) is programmed to evenly distribute data blocks as much as possible in each FlexVol volume across all disks in aggregate so each FlexVol could potentially use all available performance of all the data disks in the aggregate. With the approach of even data block distribution across all the data disks in an aggregate, performance throttling for a FlexVol could be done dynamically with storage QoS and does not require dedicated aggregates or RAID groups for each FlexVol to guarantee performance and provide the unused performance to a FlexVol volume which requires it. Each FlexVol could be configured as thick or thin provisioned space and later could be changed on the fly any time. Block device access with storage area network (SAN) protocols such as iSCSI, Fibre Channel (FC), and Fibre Channel over Ethernet (FCoE) is done with LUN emulation similar to Loop device technique on top of a FlexVol volume; thus each LUN on WAFL file system appears as a file, yet have additional properties required for block devices. LUNs can also be configured as thick or thin provisioned and can be changed later on the fly. Due to WAFL architecture, FlexVols and LUNs can increase or decrease configured space usage on the fly. If a FlexVol contains data, internal space can be decreased no less than used space. Even though LUN size with data on it could be decreased on WAFL file system, ONTAP has no knowledge about upper-level block structure due to SAN architecture so it could truncate data and damage the file system on that LUN, so the host needs to migrate the blocks containing the data into a new LUN boundary to prevent data loss. Each FlexVol can have its own QoS, FlashPool, FlasCache or FabricPool policies.
If two FlexVol volumes are created, each on two aggregates and those aggregates owned by two different controllers, and the system administrator needs to use space from these volumes through a NAS protocol. Then they would create two file shares, one on each volume. In this case, the administrator will most probably even create different IP addresses; each will be used to access a dedicated file share. Each volume will have a single write waffinity, and there will be two buckets of space. Though even if two volumes reside on a single controller, and for example on a single aggregate (thus if the second aggregate exists, it will not be used in this case) and both volumes will be accessed through a single IP address, there will still be two write affinities, one on each volume and there always will be two separate buckets of space. Therefore, the more volumes you have, the more write waffinities you'll have (better parallelization and thus better CPU utilization), but then you'll have multiple volumes (and multiple buckets for space thus multiple file shares).
Plexes
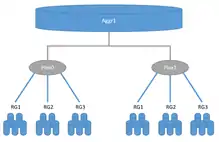
Similar to RAID-1, plexes in ONTAP systems can keep mirrored data in two places, but while conventional RAID-1 must exist within the bounds of one storage system, two plexes could be distributed between two storage systems. Each aggregate consists of one or two plexes. Conventional HA storage systems have only one plex for each aggregate, while SyncMirror local or MetroCluster configurations can have two plexes for each aggregate. On the other hand, each plex includes underlying storage space from one or more NetApp RAID groups or LUNs from third-party storage systems (see FlexArray) in a single plex similarly to RAID-0. If an aggregate consists of two plexes, one plex is considered a master and second as a slave; slaves must consist of exactly the same RAID configuration and drives. For example, if we have an aggregate consisting of two plexes where the master plex consists of 21 data and 3 1.8 TB SAS parity drives in RAID-TEC, then the slave plex must consist of 21 data and 3 1.8 TB SAS parity drives in RAID-TEC. The second example, if we have an aggregate consisted of two plexes where master plex consists of one RAID 17 data and 3 parity SAS drives 1.8 TB configured as RAID-TEC and second RAID in the master plex is RAID-DP with 2 data and 2 parity SSD 960 GB. The second plex must have the same configuration: one RAID 17 data and 3 parity SAS drives 1.8 TB configured as RAID-TEC, and the second RAID in the slave plex is RAID-DP with 2 data and 2 parity SSD 960 GB. MetroCluster configurations use SyncMirror technology for synchronous data replication. There are two SyncMirror options: MetroCluster and Local SyncMirror, both using the same plex technique for synchronous replication of data between two plexes. Local SyncMirror creates both plexes in a single controller and is often used for additional security to prevent failure for an entire disk shelf in a storage system. MetroCluster allows data to be replicated between two storage systems. Each storage system could consist of one controller or be configured as an HA pair with two controllers. In a single HA pair, it is possible to have two controllers in separate chassis and distance from each other could be tens of meters, while in MetroCluster configuration distance could be up to 300 km.
Nonvolatile memory
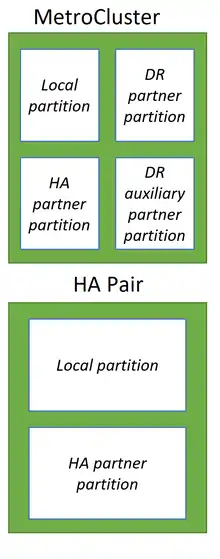
Like many competitors, NetApp ONTAP systems utilizing memory as a much faster storage medium for accepting and caching data from hosts and, most importantly, for data optimization before writes which greatly improves the performance of such storage systems. While competitors widely using non-volatile random-access memory (NVRAM) to preserve data in it during unexpected events like a reboot for both write caching and data optimization, NetApp ONTAP systems using ordinary random-access memory (RAM) for data optimization and dedicated NVRAM or NVDIMM for logging of initial data in an unchanged state as they came from hosts similarly as transaction logging done in Relational databases. So in case of disaster, naturally, RAM will be automatically cleared after reboot, and data stored in non-volatile memory in the form of logs called NVLOGs will survive after reboot and will be used for restore consistency. All changes and optimizations in ONTAP systems done only in RAM, which helps to reduce the size of non-volatile memory for ONTAP systems. After optimizations data from hosts structured in Tetris-like manner, optimized and prepared with passing few stages (i.e., WAFL and RAID) to be written in underlying disks in RAID groups on the aggregate where data are going to be stored. After optimizations, data is going to be sequentially written on disks as part of the Consistency Point (CP) transaction. Data written to aggregates will contain necessary WAFL metadata and RAID parity so no additional read from data disks, calculate and write to parity disks operations will occur as with traditional RAID-6 and RAID-4 groups. CP at first creating system snapshot on an aggregate where data are going to be written, then optimized and prepared data from RAM written sequentially as a single transaction to the aggregate, if it fails, the whole transaction fails in case of a sudden reboot which allows WAFL file system always to be consistent. In case of successful CP transaction new active file system point is propagated and corresponding NVLOGs cleared. All data are always going to be written to a new place, and no rewrites can occur. Data blocks deleted by hosts marked as free so they could be used later on next CP cycles and the system will not run out of space with the always-write-new-data-to-new-place policy of WAFL. Only NVLOGs in HA storage systems is replicated synchronously between two controllers for HA storage system failover capability, which helps to reduce overall system memory protection overheads. In a storage system with two controllers in HA configuration or MetroCluster with one controller on each site, each of the two controllers divides its own non-volatile memory into two pieces: local and its partner. In MetroCluster configuration with four nodes, each non-volatile memory divided into next pieces: local, local partner's and remote partner's.[7]
Starting with the All-Flash FAS A800 system, NetApp replaced the NVRAM PCI module with NVDIMMs connected to the memory bus, increasing the performance.
See also
- Comparison of file systems
- List of file systems
- NetApp
- NetApp FAS
- ONTAP Operation System, used in NetApp storage systems
Notes
- "Storage limits". library.netapp.com.
- "NetApp Volume Encryption, The Nitty Gritty | IOPS.ca".
- "Is WAFL a File System?". Blogs.netapp.com. Archived from the original on July 15, 2014.
- Dave Hitz; James Lau; Michael Malcolm (January 19, 1994). File System Design for an NFS File Server Appliance (PDF). USENIX Winter 1994.
- Parisi, Justin (July 14, 2017). "Running VMware on ONTAP? Why you should consider upgrading to ONTAP 9.2".
- "POSIX Access Control Lists on Linux". Suse.de. Archived from the original on 2007-01-24.
- "Clustered Data ONTAP® 8.3. MetroCluster™ Management and Disaster Recovery Guide: NVRAM and NVMEM cache mirroring in a MetroCluster configuration". NetApp. 1 September 2015. Archived from the original (url) on 2018-01-24. Retrieved 24 January 2018.
External links
- Official website
- File System Design for an NFS File Server Appliance (PDF)
- U.S. Patent 5,819,292 - Method for maintaining consistent states of a file system and for creating user-accessible read-only copies of a file system - October 6, 1998