Association rule learning
Association rule learning is a rule-based machine learning method for discovering interesting relations between variables in large databases. It is intended to identify strong rules discovered in databases using some measures of interestingness.[1]
| Part of a series on |
| Machine learning and data mining |
|---|
Based on the concept of strong rules, Rakesh Agrawal, Tomasz Imieliński and Arun Swami[2] introduced association rules for discovering regularities between products in large-scale transaction data recorded by point-of-sale (POS) systems in supermarkets. For example, the rule found in the sales data of a supermarket would indicate that if a customer buys onions and potatoes together, they are likely to also buy hamburger meat. Such information can be used as the basis for decisions about marketing activities such as, e.g., promotional pricing or product placements.

In addition to the above example from market basket analysis association rules are employed today in many application areas including Web usage mining, intrusion detection, continuous production, and bioinformatics. In contrast with sequence mining, association rule learning typically does not consider the order of items either within a transaction or across transactions.
Definition
| transaction ID | milk | bread | butter | beer | diapers |
|---|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 0 | 0 |
| 2 | 0 | 0 | 1 | 0 | 0 |
| 3 | 0 | 0 | 0 | 1 | 1 |
| 4 | 1 | 1 | 1 | 0 | 0 |
| 5 | 0 | 1 | 0 | 0 | 0 |
Following the original definition by Agrawal, Imieliński, Swami[2] the problem of association rule mining is defined as:
Let be a set of binary attributes called items.


Let be a set of transactions called the database.

Each transaction in has a unique transaction ID and contains a subset of the items in .


A rule is defined as an implication of the form:
, where .


In Agrawal, Imieliński, Swami[2] a rule is defined only between a set and a single item, for .


Every rule is composed by two different sets of items, also known as itemsets, and , where is called antecedent or left-hand-side (LHS) and consequent or right-hand-side (RHS).


To illustrate the concepts, we use a small example from the supermarket domain. The set of items is and in the table is shown a small database containing the items, where, in each entry, the value 1 means the presence of the item in the corresponding transaction, and the value 0 represents the absence of an item in that transaction.

An example rule for the supermarket could be meaning that if butter and bread are bought, customers also buy milk.

Note: this example is extremely small. In practical applications, a rule needs a support of several hundred transactions before it can be considered statistically significant,[3] and datasets often contain thousands or millions of transactions.
Useful Concepts
In order to select interesting rules from the set of all possible rules, constraints on various measures of significance and interest are used. The best-known constraints are minimum thresholds on support and confidence.
Let be itemsets, an association rule and a set of transactions of a given database.


Support
Support is an indication of how frequently the itemset appears in the dataset.
The support of with respect to is defined as the proportion of transactions in the dataset which contains the itemset .


In the example dataset, the itemset has a support of since it occurs in 20% of all transactions (1 out of 5 transactions). The argument of is a set of preconditions, and thus becomes more restrictive as it grows (instead of more inclusive).[4]



Furthermore, the itemset has a support of as it appears in 20% of all transactions as well.

Confidence
Confidence is an indication of how often the rule has been found to be true.
The confidence value of a rule, , with respect to a set of transactions , is the proportion of the transactions that contains which also contains .
Confidence is defined as:

For example, the rule has a confidence of in the database, which means that for 100% of the transactions containing butter and bread the rule is correct (100% of the times a customer buys butter and bread, milk is bought as well).

Note that means the support of the union of the items in X and Y. This is somewhat confusing since we normally think in terms of probabilities of events and not sets of items. We can rewrite as the probability , where and are the events that a transaction contains itemset and , respectively.[5]




Thus confidence can be interpreted as an estimate of the conditional probability , the probability of finding the RHS of the rule in transactions under the condition that these transactions also contain the LHS.[4][6]

Lift
The lift of a rule is defined as:

or the ratio of the observed support to that expected if X and Y were independent.
For example, the rule has a lift of .


If the rule had a lift of 1, it would imply that the probability of occurrence of the antecedent and that of the consequent are independent of each other. When two events are independent of each other, no rule can be drawn involving those two events.
If the lift is > 1, that lets us know the degree to which those two occurrences are dependent on one another, and makes those rules potentially useful for predicting the consequent in future data sets.
If the lift is < 1, that lets us know the items are substitute to each other. This means that presence of one item has negative effect on presence of other item and vice versa.
The value of lift is that it considers both the support of the rule and the overall data set.[4]
Conviction
The conviction of a rule is defined as .[7]

For example, the rule has a conviction of , and can be interpreted as the ratio of the expected frequency that X occurs without Y (that is to say, the frequency that the rule makes an incorrect prediction) if X and Y were independent divided by the observed frequency of incorrect predictions. In this example, the conviction value of 1.2 shows that the rule would be incorrect 20% more often (1.2 times as often) if the association between X and Y was purely random chance.

Alternative measures of interestingness
In addition to confidence, other measures of interestingness for rules have been proposed. Some popular measures are:
Several more measures are presented and compared by Tan et al.[11] and by Hahsler.[5] Looking for techniques that can model what the user has known (and using these models as interestingness measures) is currently an active research trend under the name of "Subjective Interestingness."
Process
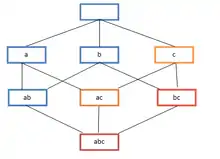

Association rules are usually required to satisfy a user-specified minimum support and a user-specified minimum confidence at the same time. Association rule generation is usually split up into two separate steps:
- A minimum support threshold is applied to find all frequent itemsets in a database.
- A minimum confidence constraint is applied to these frequent itemsets in order to form rules.
While the second step is straightforward, the first step needs more attention.
Finding all frequent itemsets in a database is difficult since it involves searching all possible itemsets (item combinations). The set of possible itemsets is the power set over and has size (excluding the empty set which is not a valid itemset). Although the size of the power-set grows exponentially in the number of items in , efficient search is possible using the downward-closure property of support[2][12] (also called anti-monotonicity[13]) which guarantees that for a frequent itemset, all its subsets are also frequent and thus no infrequent itemset can be a subset of a frequent itemset. Exploiting this property, efficient algorithms (e.g., Apriori[14] and Eclat[15]) can find all frequent itemsets.

History
The concept of association rules was popularised particularly due to the 1993 article of Agrawal et al.,[2] which has acquired more than 18,000 citations according to Google Scholar, as of August 2015, and is thus one of the most cited papers in the Data Mining field. However, what is now called "association rules" is introduced already in the 1966 paper[16] on GUHA, a general data mining method developed by Petr Hájek et al.[17]
An early (circa 1989) use of minimum support and confidence to find all association rules is the Feature Based Modeling framework, which found all rules with and greater than user defined constraints.[18]


Statistically sound associations
One limitation of the standard approach to discovering associations is that by searching massive numbers of possible associations to look for collections of items that appear to be associated, there is a large risk of finding many spurious associations. These are collections of items that co-occur with unexpected frequency in the data, but only do so by chance. For example, suppose we are considering a collection of 10,000 items and looking for rules containing two items in the left-hand-side and 1 item in the right-hand-side. There are approximately 1,000,000,000,000 such rules. If we apply a statistical test for independence with a significance level of 0.05 it means there is only a 5% chance of accepting a rule if there is no association. If we assume there are no associations, we should nonetheless expect to find 50,000,000,000 rules. Statistically sound association discovery[19][20] controls this risk, in most cases reducing the risk of finding any spurious associations to a user-specified significance level.
Algorithms
Many algorithms for generating association rules have been proposed.
Some well-known algorithms are Apriori, Eclat and FP-Growth, but they only do half the job, since they are algorithms for mining frequent itemsets. Another step needs to be done after to generate rules from frequent itemsets found in a database.
Apriori algorithm
Apriori[14] uses a breadth-first search strategy to count the support of itemsets and uses a candidate generation function which exploits the downward closure property of support.
Eclat algorithm
Eclat[15] (alt. ECLAT, stands for Equivalence Class Transformation) is a depth-first search algorithm based on set intersection. It is suitable for both sequential as well as parallel execution with locality-enhancing properties.[21][22]
FP-growth algorithm
FP stands for frequent pattern.[23]
In the first pass, the algorithm counts the occurrences of items (attribute-value pairs) in the dataset of transactions, and stores these counts in a 'header table'. In the second pass, it builds the FP-tree structure by inserting transactions into a trie.
Items in each transaction have to be sorted by descending order of their frequency in the dataset before being inserted so that the tree can be processed quickly. Items in each transaction that do not meet the minimum support requirement are discarded. If many transactions share most frequent items, the FP-tree provides high compression close to tree root.
Recursive processing of this compressed version of the main dataset grows frequent item sets directly, instead of generating candidate items and testing them against the entire database (as in the apriori algorithm).
Growth begins from the bottom of the header table i.e. the item with the smallest support by finding all sorted transactions that end in that item. Call this item .
A new conditional tree is created which is the original FP-tree projected onto . The supports of all nodes in the projected tree are re-counted with each node getting the sum of its children counts. Nodes (and hence subtrees) that do not meet the minimum support are pruned. Recursive growth ends when no individual items conditional on meet the minimum support threshold. The resulting paths from root to will be frequent itemsets. After this step, processing continues with the next least-supported header item of the original FP-tree.
Once the recursive process has completed, all frequent item sets will have been found, and association rule creation begins.[24]
ASSOC
The ASSOC procedure[25] is a GUHA method which mines for generalized association rules using fast bitstrings operations. The association rules mined by this method are more general than those output by apriori, for example "items" can be connected both with conjunction and disjunctions and the relation between antecedent and consequent of the rule is not restricted to setting minimum support and confidence as in apriori: an arbitrary combination of supported interest measures can be used.
OPUS search
OPUS is an efficient algorithm for rule discovery that, in contrast to most alternatives, does not require either monotone or anti-monotone constraints such as minimum support.[26] Initially used to find rules for a fixed consequent[26][27] it has subsequently been extended to find rules with any item as a consequent.[28] OPUS search is the core technology in the popular Magnum Opus association discovery system.
Lore
A famous story about association rule mining is the "beer and diaper" story. A purported survey of behavior of supermarket shoppers discovered that customers (presumably young men) who buy diapers tend also to buy beer. This anecdote became popular as an example of how unexpected association rules might be found from everyday data. There are varying opinions as to how much of the story is true.[29] Daniel Powers says:[29]
In 1992, Thomas Blischok, manager of a retail consulting group at Teradata, and his staff prepared an analysis of 1.2 million market baskets from about 25 Osco Drug stores. Database queries were developed to identify affinities. The analysis "did discover that between 5:00 and 7:00 p.m. that consumers bought beer and diapers". Osco managers did NOT exploit the beer and diapers relationship by moving the products closer together on the shelves.
Other types of association rule mining
Multi-Relation Association Rules: Multi-Relation Association Rules (MRAR) are association rules where each item may have several relations. These relations indicate indirect relationship between the entities. Consider the following MRAR where the first item consists of three relations live in, nearby and humid: “Those who live in a place which is nearby a city with humid climate type and also are younger than 20 -> their health condition is good”. Such association rules are extractable from RDBMS data or semantic web data.[30]
Contrast set learning is a form of associative learning. Contrast set learners use rules that differ meaningfully in their distribution across subsets.[31][32]
Weighted class learning is another form of associative learning in which weight may be assigned to classes to give focus to a particular issue of concern for the consumer of the data mining results.
High-order pattern discovery facilitate the capture of high-order (polythetic) patterns or event associations that are intrinsic to complex real-world data. [33]
K-optimal pattern discovery provides an alternative to the standard approach to association rule learning that requires that each pattern appear frequently in the data.
Approximate Frequent Itemset mining is a relaxed version of Frequent Itemset mining that allows some of the items in some of the rows to be 0.[34]
Generalized Association Rules hierarchical taxonomy (concept hierarchy)
Quantitative Association Rules categorical and quantitative data
Interval Data Association Rules e.g. partition the age into 5-year-increment ranged
Sequential pattern mining discovers subsequences that are common to more than minsup sequences in a sequence database, where minsup is set by the user. A sequence is an ordered list of transactions.[35]
Subspace Clustering, a specific type of Clustering high-dimensional data, is in many variants also based on the downward-closure property for specific clustering models.[36]
Warmr is shipped as part of the ACE data mining suite. It allows association rule learning for first order relational rules.[37]
See also
References
- Piatetsky-Shapiro, Gregory (1991), Discovery, analysis, and presentation of strong rules, in Piatetsky-Shapiro, Gregory; and Frawley, William J.; eds., Knowledge Discovery in Databases, AAAI/MIT Press, Cambridge, MA.
- Agrawal, R.; Imieliński, T.; Swami, A. (1993). "Mining association rules between sets of items in large databases". Proceedings of the 1993 ACM SIGMOD international conference on Management of data - SIGMOD '93. p. 207. CiteSeerX 10.1.1.40.6984. doi:10.1145/170035.170072. ISBN 978-0897915922. S2CID 490415.
- Khalid, Saifullah (2018). "Apriori Algorithm". Applied Computational Intelligence and Soft Computing in Engineering. Egypt: Hindawi Limited. pp. 288–289. ISBN 9781522531296.
- Hahsler, Michael (2005). "Introduction to arules – A computational environment for mining association rules and frequent item sets" (PDF). Journal of Statistical Software. doi:10.18637/jss.v014.i15.
- Michael Hahsler (2015). A Probabilistic Comparison of Commonly Used Interest Measures for Association Rules. http://michael.hahsler.net/research/association_rules/measures.html
- Hipp, J.; Güntzer, U.; Nakhaeizadeh, G. (2000). "Algorithms for association rule mining --- a general survey and comparison". ACM SIGKDD Explorations Newsletter. 2: 58–64. CiteSeerX 10.1.1.38.5305. doi:10.1145/360402.360421. S2CID 9248096.
- Brin, Sergey; Motwani, Rajeev; Ullman, Jeffrey D.; Tsur, Shalom (1997). "Dynamic itemset counting and implication rules for market basket data". Proceedings of the 1997 ACM SIGMOD international conference on Management of data - SIGMOD '97. pp. 255–264. CiteSeerX 10.1.1.41.6476. doi:10.1145/253260.253325. ISBN 978-0897919111. S2CID 15385590.
- Omiecinski, E.R. (2003). "Alternative interest measures for mining associations in databases". IEEE Transactions on Knowledge and Data Engineering. 15: 57–69. CiteSeerX 10.1.1.329.5344. doi:10.1109/TKDE.2003.1161582.
- Aggarwal, Charu C.; Yu, Philip S. (1998). "A new framework for itemset generation". Proceedings of the seventeenth ACM SIGACT-SIGMOD-SIGART symposium on Principles of database systems - PODS '98. pp. 18–24. CiteSeerX 10.1.1.24.714. doi:10.1145/275487.275490. ISBN 978-0897919968. S2CID 11934586.
- Piatetsky-Shapiro, Gregory; Discovery, analysis, and presentation of strong rules, Knowledge Discovery in Databases, 1991, pp. 229-248
- Tan, Pang-Ning; Kumar, Vipin; Srivastava, Jaideep (2004). "Selecting the right objective measure for association analysis". Information Systems. 29 (4): 293–313. CiteSeerX 10.1.1.331.4740. doi:10.1016/S0306-4379(03)00072-3.
- Tan, Pang-Ning; Michael, Steinbach; Kumar, Vipin (2005). "Chapter 6. Association Analysis: Basic Concepts and Algorithms" (PDF). Introduction to Data Mining. Addison-Wesley. ISBN 978-0-321-32136-7.
- Jian Pei; Jiawei Han; Lakshmanan, L.V.S. (2001). "Mining frequent itemsets with convertible constraints". Proceedings 17th International Conference on Data Engineering. pp. 433–442. CiteSeerX 10.1.1.205.2150. doi:10.1109/ICDE.2001.914856. ISBN 978-0-7695-1001-9. S2CID 1080975.
- Agrawal, Rakesh; and Srikant, Ramakrishnan; Fast algorithms for mining association rules in large databases Archived 2015-02-25 at the Wayback Machine, in Bocca, Jorge B.; Jarke, Matthias; and Zaniolo, Carlo; editors, Proceedings of the 20th International Conference on Very Large Data Bases (VLDB), Santiago, Chile, September 1994, pages 487-499
- Zaki, M. J. (2000). "Scalable algorithms for association mining". IEEE Transactions on Knowledge and Data Engineering. 12 (3): 372–390. CiteSeerX 10.1.1.79.9448. doi:10.1109/69.846291.
- Hájek, P.; Havel, I.; Chytil, M. (1966). "The GUHA method of automatic hypotheses determination". Computing. 1 (4): 293–308. doi:10.1007/BF02345483. S2CID 10511114.
- Hájek, Petr; Rauch, Jan; Coufal, David; Feglar, Tomáš (2004). "The GUHA Method, Data Preprocessing and Mining". Database Support for Data Mining Applications. Lecture Notes in Computer Science. 2682. pp. 135–153. doi:10.1007/978-3-540-44497-8_7. ISBN 978-3-540-22479-2.
- Webb, Geoffrey (1989). "A Machine Learning Approach to Student Modelling". Proceedings of the Third Australian Joint Conference on Artificial Intelligence (AI 89): 195–205.
- Webb, Geoffrey I. (2007). "Discovering Significant Patterns". Machine Learning. 68: 1–33. doi:10.1007/s10994-007-5006-x.
- Gionis, Aristides; Mannila, Heikki; Mielikäinen, Taneli; Tsaparas, Panayiotis (2007). "Assessing data mining results via swap randomization". ACM Transactions on Knowledge Discovery from Data. 1 (3): 14–es. CiteSeerX 10.1.1.141.2607. doi:10.1145/1297332.1297338. S2CID 52305658.
- Zaki, Mohammed Javeed; Parthasarathy, Srinivasan; Ogihara, Mitsunori; Li, Wei (1997). "New Algorithms for Fast Discovery of Association Rules": 283–286. CiteSeerX 10.1.1.42.3283. hdl:1802/501. Cite journal requires
|journal=(help) - Zaki, Mohammed J.; Parthasarathy, Srinivasan; Ogihara, Mitsunori; Li, Wei (1997). "Parallel Algorithms for Discovery of Association Rules". Data Mining and Knowledge Discovery. 1 (4): 343–373. doi:10.1023/A:1009773317876. S2CID 10038675.
- Han (2000). "Mining Frequent Patterns Without Candidate Generation". Proceedings of the 2000 ACM SIGMOD international conference on Management of data - SIGMOD '00. Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data. SIGMOD '00. pp. 1–12. CiteSeerX 10.1.1.40.4436. doi:10.1145/342009.335372. ISBN 978-1581132175. S2CID 6059661.
- Witten, Frank, Hall: Data mining practical machine learning tools and techniques, 3rd edition
- Hájek, Petr; Havránek, Tomáš (1978). Mechanizing Hypothesis Formation: Mathematical Foundations for a General Theory. Springer-Verlag. ISBN 978-3-540-08738-0.
- Webb, Geoffrey I. (1995); OPUS: An Efficient Admissible Algorithm for Unordered Search, Journal of Artificial Intelligence Research 3, Menlo Park, CA: AAAI Press, pp. 431-465 online access
- Bayardo, Roberto J., Jr.; Agrawal, Rakesh; Gunopulos, Dimitrios (2000). "Constraint-based rule mining in large, dense databases". Data Mining and Knowledge Discovery. 4 (2): 217–240. doi:10.1023/A:1009895914772. S2CID 5120441.
- Webb, Geoffrey I. (2000). "Efficient search for association rules". Proceedings of the sixth ACM SIGKDD international conference on Knowledge discovery and data mining - KDD '00. pp. 99–107. CiteSeerX 10.1.1.33.1309. doi:10.1145/347090.347112. ISBN 978-1581132335. S2CID 5444097.
- "DSS News: Vol. 3, No. 23".
- Ramezani, Reza, Mohamad Sunni ee, and Mohammad Ali Nematbakhsh; MRAR: Mining Multi-Relation Association Rules, Journal of Computing and Security, 1, no. 2 (2014)
- GI Webb and S. Butler and D. Newlands (2003). On Detecting Differences Between Groups. KDD'03 Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.
- Menzies, T.; Ying Hu (2003). "Computing practices - Data mining for very busy people". Computer. 36 (11): 22–29. doi:10.1109/MC.2003.1244531.
- Wong, A.K.C.; Yang Wang (1997). "High-order pattern discovery from discrete-valued data". IEEE Transactions on Knowledge and Data Engineering. 9 (6): 877–893. CiteSeerX 10.1.1.189.1704. doi:10.1109/69.649314.
- Liu, Jinze; Paulsen, Susan; Sun, Xing; Wang, Wei; Nobel, Andrew; Prins, Jan (2006). "Mining Approximate Frequent Itemsets in the Presence of Noise: Algorithm and Analysis". Proceedings of the 2006 SIAM International Conference on Data Mining. pp. 407–418. CiteSeerX 10.1.1.215.3599. doi:10.1137/1.9781611972764.36. ISBN 978-0-89871-611-5.
- Zaki, Mohammed J. (2001); SPADE: An Efficient Algorithm for Mining Frequent Sequences, Machine Learning Journal, 42, pp. 31–60
- Zimek, Arthur; Assent, Ira; Vreeken, Jilles (2014). Frequent Pattern Mining. pp. 403–423. doi:10.1007/978-3-319-07821-2_16. ISBN 978-3-319-07820-5.
- King, R. D.; Srinivasan, A.; Dehaspe, L. (Feb 2001). "Warmr: a data mining tool for chemical data". J Comput Aided Mol Des. 15 (2): 173–81. Bibcode:2001JCAMD..15..173K. doi:10.1023/A:1008171016861. PMID 11272703. S2CID 3055046.
Bibliographies
- Annotated Bibliography on Association Rules by M. Hahsler