Fuzzy clustering
Fuzzy clustering (also referred to as soft clustering or soft k-means) is a form of clustering in which each data point can belong to more than one cluster.
| Part of a series on |
| Machine learning and data mining |
|---|
Clustering or cluster analysis involves assigning data points to clusters such that items in the same cluster are as similar as possible, while items belonging to different clusters are as dissimilar as possible. Clusters are identified via similarity measures. These similarity measures include distance, connectivity, and intensity. Different similarity measures may be chosen based on the data or the application.[1]
Comparison to hard clustering
In non-fuzzy clustering (also known as hard clustering), data is divided into distinct clusters, where each data point can only belong to exactly one cluster. In fuzzy clustering, data points can potentially belong to multiple clusters. For example, an apple can be red or green (hard clustering), but an apple can also be red AND green (fuzzy clustering). Here, the apple can be red to a certain degree as well as green to a certain degree. Instead of the apple belonging to green [green = 1] and not red [red = 0], the apple can belong to green [green = 0.5] and red [red = 0.5]. These value are normalized between 0 and 1; however, they do not represent probabilities, so the two values do not need to add up to 1.
Membership
Membership grades are assigned to each of the data points (tags). These membership grades indicate the degree to which data points belong to each cluster. Thus, points on the edge of a cluster, with lower membership grades, may be in the cluster to a lesser degree than points in the center of cluster.
Fuzzy C-means clustering
One of the most widely used fuzzy clustering algorithms is the Fuzzy C-means clustering (FCM) Algorithm.
History
Fuzzy c-means (FCM) clustering was developed by J.C. Dunn in 1973,[2] and improved by J.C. Bezdek in 1981.[3]
General description
The fuzzy c-means algorithm is very similar to the k-means algorithm:
- Choose a number of clusters.
- Assign coefficients randomly to each data point for being in the clusters.
- Repeat until the algorithm has converged (that is, the coefficients' change between two iterations is no more than , the given sensitivity threshold) :
- Compute the centroid for each cluster (shown below).
- For each data point, compute its coefficients of being in the clusters.

Centroid
Any point x has a set of coefficients giving the degree of being in the kth cluster wk(x). With fuzzy c-means, the centroid of a cluster is the mean of all points, weighted by their degree of belonging to the cluster, or, mathematically,

where m is the hyper- parameter that controls how fuzzy the cluster will be. The higher it is, the fuzzier the cluster will be in the end.
Algorithm
The FCM algorithm attempts to partition a finite collection of elements into a collection of c fuzzy clusters with respect to some given criterion.


Given a finite set of data, the algorithm returns a list of cluster centres and a partition matrix


, where each element, , tells the degree to which element, , belongs to cluster .




The FCM aims to minimize an objective function:

where:

Comparison to K-means clustering
K-means clustering also attempts to minimize the objective function shown above. This method differs from the k-means objective function by the addition of the membership values and the fuzzifier, , with . The fuzzifier determines the level of cluster fuzziness. A large results in smaller membership values, , and hence, fuzzier clusters. In the limit , the memberships, , converge to 0 or 1, which implies a crisp partitioning. In the absence of experimentation or domain knowledge, is commonly set to 2. The algorithm minimizes intra-cluster variance as well, but has the same problems as 'k'-means; the minimum is a local minimum, and the results depend on the initial choice of weights.




Related algorithms
Fuzzy C-means (FCM) with automatically determined for the number of clusters could enhance the detection accuracy.[4] Using a mixture of Gaussians along with the expectation-maximization algorithm is a more statistically formalized method which includes some of these ideas: partial membership in classes.
Example
To better understand this principle, a classic example of mono-dimensional data is given below on an x axis.
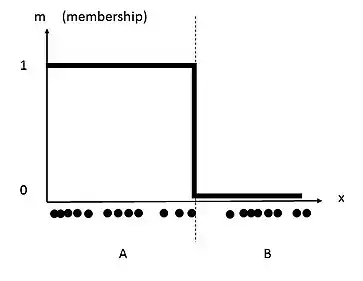
This data set can be traditionally grouped into two clusters. By selecting a threshold on the x-axis, the data is separated into two clusters. The resulting clusters are labelled 'A' and 'B', as seen in the following image. Each point belonging to the data set would therefore have a membership coefficient of 1 or 0. This membership coefficient of each corresponding data point is represented by the inclusion of the y-axis.
In fuzzy clustering, each data point can have membership to multiple clusters. By relaxing the definition of membership coefficients from strictly 1 or 0, these values can range from any value from 1 to 0. The following image shows the data set from the previous clustering, but now fuzzy c-means clustering is applied. First, a new threshold value defining two clusters may be generated. Next, new membership coefficients for each data point are generated based on clusters centroids, as well as distance from each cluster centroid.
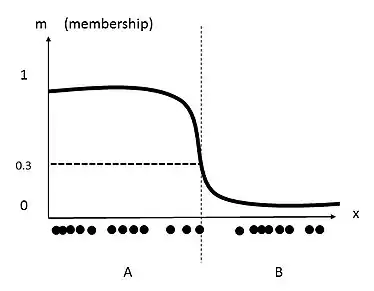
As one can see, the middle data point belongs to cluster A and cluster B. the value of 0.3 is this data point's membership coefficient for cluster A .[5]
Applications
Clustering problems have applications in surface science, biology, medicine, psychology, economics, and many other disciplines.[6]
Bioinformatics
In the field of bioinformatics, clustering is used for a number of applications. One use is as a pattern recognition technique to analyze gene expression data from microarrays or other technology.[7] In this case, genes with similar expression patterns are grouped into the same cluster, and different clusters display distinct, well-separated patterns of expression. Use of clustering can provide insight into gene function and regulation.[6] Because fuzzy clustering allows genes to belong to more than one cluster, it allows for the identification of genes that are conditionally co-regulated or co-expressed.[8] For example, one gene may be acted on by more than one Transcription factor, and one gene may encode a protein that has more than one function. Thus, fuzzy clustering is more appropriate than hard clustering.
Image analysis
Fuzzy c-means has been a very important tool for image processing in clustering objects in an image. In the 70's, mathematicians introduced the spatial term into the FCM algorithm to improve the accuracy of clustering under noise.[9] Furthermore, FCM algorithms have been used to distinguish between different activities using image-based features such as the Hu and the Zernike Moments.[10] Alternatively, A fuzzy logic model can be described on fuzzy sets that are defined on three components of the HSL color space HSL and HSV; The membership functions aim to describe colors follow the human intuition of color identification.[11]
Marketing
In marketing, customers can be grouped into fuzzy clusters based on their needs, brand choices, psycho-graphic profiles, or other marketing related partitions.
Image processing example

Image segmentation using k-means clustering algorithms has long been used for pattern recognition, object detection, and medical imaging. However, due to real world limitations such as noise, shadowing, and variations in cameras, traditional hard clustering is often unable to reliably perform image processing tasks as stated above.[12] Fuzzy clustering has been proposed as a more applicable algorithm in the performance to these tasks. Given is gray scale image that has undergone fuzzy clustering in Matlab.[13] The original image is seen next to a clustered image. Colors are used to give a visual representation of the three distinct clusters used to identify the membership of each pixel. Below, a chart is given that defines the fuzzy membership coefficients of their corresponding intensity values.
Depending on the application for which the fuzzy clustering coefficients are to be used, different pre-processing techniques can be applied to RGB images. RGB to HCL conversion is common practice.[14]
See also
- FLAME Clustering
- Cluster Analysis
- Expectation-maximization algorithm (a similar, but more statistically formalized method)
References
- "Fuzzy Clustering". reference.wolfram.com. Retrieved 2016-04-26.
- Dunn, J. C. (1973-01-01). "A Fuzzy Relative of the ISODATA Process and Its Use in Detecting Compact Well-Separated Clusters". Journal of Cybernetics. 3 (3): 32–57. doi:10.1080/01969727308546046. ISSN 0022-0280.
- Bezdek, James C. (1981). Pattern Recognition with Fuzzy Objective Function Algorithms. ISBN 0-306-40671-3.
- Said, E El-Khamy; Rowayda A Sadek; Mohamed A El-Khoreby (October 2015). "An efficient brain mass detection with adaptive clustered based fuzzy C-mean and thresholding". 2015 IEEE International Conference on Signal and Image Processing Applications (ICSIPA): 429–433.
- "Clustering - Fuzzy C-means". home.deib.polimi.it. Retrieved 2017-05-01.
- Ben-Dor, Amir; Shamir, Ron; Yakhini, Zohar (1999-10-01). "Clustering Gene Expression Patterns". Journal of Computational Biology. 6 (3–4): 281–297. CiteSeerX 10.1.1.34.5341. doi:10.1089/106652799318274. ISSN 1066-5277. PMID 10582567.
- Valafar, Faramarz (2002-12-01). "Pattern Recognition Techniques in Microarray Data Analysis". Annals of the New York Academy of Sciences. 980 (1): 41–64. CiteSeerX 10.1.1.199.6445. doi:10.1111/j.1749-6632.2002.tb04888.x. ISSN 1749-6632. PMID 12594081.
- Valafar F. Pattern recognition techniques in microarray data analysis. Annals of the New York Academy of Sciences. 2002 Dec 1;980(1):41-64.
- Ahmed, Mohamed N.; Yamany, Sameh M.; Mohamed, Nevin; Farag, Aly A.; Moriarty, Thomas (2002). "A Modified Fuzzy C-Means Algorithm for Bias Field Estimation and Segmentation of MRI Data" (PDF). IEEE Transactions on Medical Imaging. 21 (3): 193–199. CiteSeerX 10.1.1.331.9742. doi:10.1109/42.996338. PMID 11989844..
- Banerjee, Tanvi (2014). "Day or Night Activity Recognition From Video Using Fuzzy Clustering Techniques". IEEE Transactions on Fuzzy Systems. 22 (3): 483–493. CiteSeerX 10.1.1.652.2819. doi:10.1109/TFUZZ.2013.2260756.
- Alireza, Kashani; Kashani, Amir; Milani, Nargess; Akhlaghi, Peyman; Khezri, Kaveh (2008). Robust Color Classification Using Fuzzy Reasoning and Genetic Algorithms in RoboCup Soccer Leagues. Robocup. Lecture Notes in Computer Science. 5001. pp. 548–555. doi:10.1007/978-3-540-68847-1_59. ISBN 978-3-540-68846-4.
- Yang, Yong (2009). "Image segmentation based on fuzzy clustering with neighborhood information" (PDF). Optica Applicata. XXXIX.
- "Fuzzy Clustering - MATLAB & Simulink". www.mathworks.com. Retrieved 2017-05-03.
- Lecca, Paola (2011). Systemic Approaches in Bioinformatics and Computational Systems Biology. IGI Global. p. 9. ISBN 9781613504369.